Не
для кого не секрет, что производительность .NET не отличается особой
прытью. Связано это с тем, что .NET разрабатывался как безопасная
система, соответственно, в ней делаются все проверки, которые обычно
игнорируют либо из соображений производительности, либо от лени. Однако
.NET Framework услужливо сделает все за нас. Чем, собственно, и способен
подпортить картину производительности. Так что-же делать, если хочется
писать на .NET но производительности недостаточно. Вот в этой статье я и
попытаюсь рассмотреть некоторые принципы поднять производительность .NET
приложения.
Самое первое - смиритесь с мыслью, что написанное на .NET приложение
будет работать медленнее, чем равнозначное на C++. Однако неплохим
аргументом здесь является ускорение разработки кода, удобство отладки, в
конце концов, Microsoft сказал, что за .NET технологией будущее. Однако
не стоит отчаиваться - все в ваших силах. Есть немало способов, как и
что можно ускорить.
Оптимизация массивов.
Встречается совет, который, возможно, берет истоки в книге Э.
Троелсена "C# и платформа .NET", что включение цикла в секцию unsafe
отключает проверки границ массива, отсюда, некоторые, видимо, смогли
сделать косвенный вывод, что раз проверок нет, значит и работает
быстрее, что и было неоднократно процитировано на различных сайтах. В
корни неверное утверждение - разницы нет никакой, абсолютно. Забудьте
про это.
Как известно, в .NET существуют два типа массивов - динамические и
статические. Естественно, есть множество случаев, когда динамический
массив (ArrayList, например) удобнее, нежели статический. Но какой тип
массива эффективнее при переборе его членов?
ArrayList al = new ArrayList();
//через 'for'
int cnt = al.Count;
for (int i = 0; i < cnt; i++)
{
string s = (string)al[i];
}
//а через 'foreach' будет в 2 раза медленнее
foreach (string o in al)
{
}
Практика показывает, что скорость выборки из них одинаковая, если
применить правильный подход. Как известно массив можно перебрать через
for и через foreach. Так вот, на статическом массиве for и foreach
абсолютно равнозначны по производительности, а на ArrayList'e foreach
работает ровно в 2 раза медленнее чем for.
Естественно, при использовании for надо прекэшировать верхнюю границу
массива, а не вызывать метод или свойство на каждой итерации
возвращающее это значение.
Вот мой совет - используйте for вместо foreach, и вам будет все
равно, какого типа у вас массив. Еще одно "за", почему стоит
использовать именно for, будет приведено в разделе "оптимизация managed
heap".
Еще одно правило - не храните в динамических массивах value типы
(int'ы всякие), время на boxing и unboxing чрезвычайно высоко,
производительность падает в 3,6 раза. Во второй версии C# эта проблема
должна быть решена применением list'ов, а пока можно обойтись
Оптимизация managed heap.
Для работы с памятью с целью хранения объектов .NET использует
managed heap (куча). В сущности это менеджер выделения памяти, который
ведет внутри себя лог всех обращений. Очень удобная штука, если не
любите за собой подчищать.
Но с удобством вы получаете и пагубную привычку совсем не следить за
памятью. А ведь в куче очень легко вызвать утечку памяти. Да, потом
вызовется Garbage Collector (GC). Но будет уже поздно - капитальный
висяк вашему приложению обеспечен. Мало того, что вы тратите время (в
сущности не вы, а менеджер кучи) на выделение памяти под объект, а потом
бросаете его за ненадобность, дак он потом еще и зависает там до
ближайшей сборки мусора. А заняв, таким образом, большую часть кучи
массой мелких объектов вы повергните GC в такой страшный аут, что он и
камня на камне от вашего приложения, претендующего на realtime, не
оставит.
Как быть? Многие советуют вызывать GC.Collect() и почаще. Дельный
совет, но не всегда хорош. Сборка мусора ресурсозатратное дело. И
вызывать его безболезненно можно только тогда когда у вас мало объектов
в куче, или, когда нет realtime процессов.
Вот несколько советов, когда лучше вызвать GC.Collect():
- Всегда после загрузки данных, но до начала реальной работы
приложения.
- Если загрузка требует больших объемов данных, то, скорее всего,
она сильно нагружает и кучу. Вызывайте сборку мусора после загрузки
очередной порции данных.
- Если realtime процесс прерывается пользователем, например каким
либо диалогом, то это самое время собрать мусор.
- Лучше написать такой код, чтобы вовсе не потребовалось собирать
мусор.
Самое лучшее - это вообще не создавать объекты, если в них нет
необходимости. Честно говоря, в вашей программе может быть масса мест,
где вы, сами того не подозревая, мусорите в куче. По мере возможности
надо находить такие места и избегать написания такого кода.
Чтобы отслеживать изменения в куче нужен profiler, например, .NET
Memory Profiler (или любой другой аналогичный). Если нет никакого, то
настоятельно советую обзавестись, а на пока хватит и счетчика из
программы Панель управления->Администрирование->Производительность.
Создайте новый набор счетчиков и добавьте счетчики #GC Handles и
Allocated Bytes/sec из набора счетчиков .NET CLR Memory.
Из названия нетрудно догадаться, что эти счетчики отображают. Если
#Bytes in all Heaps непрерывно увеличивается, а Allocated Bytes/sec
находится на одном уровне - то вы имеете утечку памяти в управляемой
куче.
Продемонстрируем это примером:
//тестовый класс которым инстанциями которого и будет заполнен массив
public class TestClass
{
private int v = 0;
public void TestMethod()
{
v++;
}
}
//собственно массив
ArrayList TestArray = new ArrayList();
//заполняем его
for (int i = 0; i < 1000; i++)
{
TestArray.Add( new TestClass() );
}
GC.Collect();
for (int iterations = 0; iterations < 10000; iterations++)
{
//--- реализация #1 ---
foreach (TestClass tc in TestArray)
tc.TestMethod();
//---------------------
//--- реализация #2 ---
int cnt = TestArray.Count;
for (int i = 0; i < cnt; i++)
{
TestClass tc = (TestClass)TestArray[i];
tc.TestMethod();
}
//---------------------
}
Для начала закомментируйте реализацию #2 и запустите скомпилированный
вариант приложения. Попутно отслеживая изменения счетчиков. Вы увидите,
следующую картину:
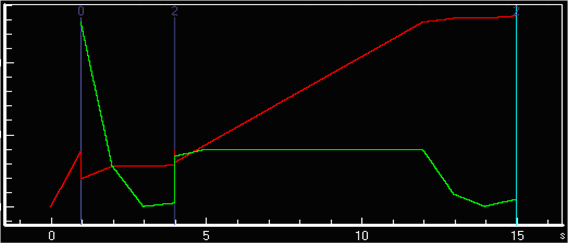
Растущая линия на ней демонстрирует счетчик #GC Handles, а другая
стабильная, но оторванная от 0 - это Allocated Bytes/sec. Значит, по
поведению графиков можно сказать, что идет постоянное выделение памяти в
куче, хотя явно этого в коде и не делается.
А теперь закомментируйте реализацию #1 и запустите скомпилированный
второй вариант реализации приложения. Сейчас мы сможем наблюдать уже
совсем другую картину:
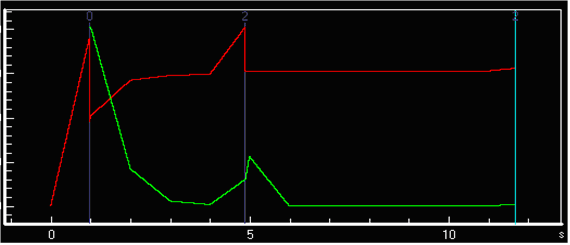
Куча стабильна, выделений памяти нет. Хотя, в сущности, алгоритм
делает тоже самое. Поэтому, рассматривая оптимизацию массивов, я и
предостерег вас от использования foreach. Хотя, следует оговорится,
подобного явления не будет наблюдаться, если вы будете обходить
статический массив посредством foreach.
Еще одним, очень интенсивным растратчиком ресурсов, являются строки
(объекты типа string). Если вы распарсериваете строки, то неизбежно
попадете на растрату памяти. Например, банальная строка вида:
int sindex = Text->IndexOf( "#RGB:" );
уже является источником растраты ресурсов. В ней, на каждой итерации,
выделяется память под строку "#RGB:". В данном случае обойти подобную
проблему очень просто - создайте внутри класса статичные переменные типа
string и используйте их для подобного рода действий.
Если при распарсеривании строк вы используете SubString() метод - это
тоже плохо. На самом деле большинства SubString'ов можно превосходно
избежать. Например, у вас есть метод ParseToken, который как либо
разбирает строку, в который из другого метода ParseString передается
часть строки изъятая посредством SubString - добавьте в метод ParseToken
еще два параметра: начало и длина куска; и передавайте туда всю строку
целиком (естественно передавать-то вы будете указатель на строку).
Методов разбора строк, имеющихся в классе string вполне достаточно, для
того чтобы вообще обойтись без использования SubString (конечно, если
вам не нужно сохранять результаты для какого либо накопления).
Академическое программирование vs производительность.
Да, следует признать удобочитаемость академического кода - кода
который написан в строгом соответствии с рекомендациями учебников и
университетскими курсами. Однако, в противоположность этому, можно
поставить правило 80/20 - т.е. программа использует 80% своего времени
на исполнение 20% своего кода. Это накладные расходы за модульность,
наследование и академическое программирование.
Если с модульностью и наследованием ничего не поделаешь, то
"правильного программирования" можно и оспорить, хотя бы в той части,
что касается внутренних членов класса, которые не должны быть доступны
снаружи и доступ к которым осуществляется через методы/свойства.
Любой из этих советов требует вызова методов, а вызов метода - весьма
накладное действие даже для C++, не говоря уже про .NET, особенно
учитывая отсутствия в нем inline. Возьмем, например, коллекцию из 10000
объектов с private объектом, который вы извлекаете методом. А теперь, у
каждого из этих объектов надо вызвать метод - итого: 10000 лишних
вызовов метода по извлечению указателя объекта, совершенно напрасно
израсходованы на то, что можно сделать без них, всего-навсего переместив
объект из private в public.
Так же эффективным советом является консолидация объектов. Например,
вы создали маленький такой объект, который хранит в себе что-либо. А
затем используете его в другом объекте путем наследования типа has-a
(т.е. включением). А теперь прикиньте, сколько лишних методов можно
исключить, просто поместив тело маленького объекта в большой.
Managed vs unmanaged.
Если вы используете Managed C++, то вы получаете еще один шанс
лучшей оптимизации кода. Это же относится к вам и в том случае, если у
вас уже есть наработки на C++, и вы осуществляете миграцию на .NET
платформу.
В MC++ есть замечательная вещь #pragma unmanaged и #pragma managed.
Эти указатели компилятору показывают, что следующий код должен быть
включен в unmanaged или в managed секцию соответственно. Помните, что
конец указателя компилятором не определяется автоматически, и вы должны
заключить интересующую вас секцию в два указателя начала и конца. В
лучшем случае, код не скомпилится, по ошибке невозможности помещения
managed объекта в unmanaged код. В худшем вы страшно уроните
производительность, и будете считать, что так и должно быть.
Весь код по умолчанию в MC++ компилится как managed. Даже если вы
добавите в проект ваши старые файлы (с прошлых С++ проектов), то они
тоже будут компилиться как managed.
Вопрос - зачем нужно собирать unmanaged код. Из соображений
производительности. Например, математика в C# работает примерно в 3 раза
медленнее, чем в MC++, что примерно еще в 3 раза медленнее чем в
unmanaged коде. Вот воскликните вы - золотое решение, затолкать все в
unmanaged и все будет быстро-быстро. Не тут-то было. Взаимодействие
managed и unmanaged кода (вызов native code процедуры из managed
объекта) - это падение производительности. Продемонстрирую это тестовыми
данными:
| Тип вызова |
Время исполнения, сек. |
| Managed -> Managed |
0,76 |
| Managed -> Unmanaged |
11,54 |
| Unmanaged -> Managed |
46,20 |
Насколько видно - разница в скорости исполнения огромная. Однако,
native code исполняется быстрее в разы, и на некотором участке (объеме
исполняемого кода) он станет эффективнее даже не смотря на затраты на
его вызов. Выглядеть это должно на графике примерно следующим образом:
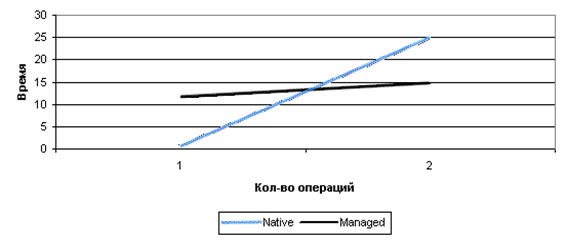
После точки пересечения - вы начнете получать преимущество от
unmanaged кода.
Так, например, перемножение матриц 4*4, которые представляют собой
unmanaged классы, производится в 2 раза быстрее, чем когда они
компилятся в managed. Но запомните, что все процедуры, от которых
зависит unmanaged контекст, тоже должны быть помещены в unmanaged. Иначе
вы попадете на 3 строку приведенной выше таблицы, т.е. вызов managed
кода из unmanaged. А это очень-очень плохо. Проверяйте свой код и
вооружитесь ILDASM'ом чтобы выявить как скомпилились ваши функции и в
какой контекст (managed или unmanaged) они попали. Как, спросите вы,
может возникнуть такое состояние как вызов managed из unmanaged. А очень
просто, наверняка в вашем коде не все заключено в классы, ведь это было
не обязательно для C++, и ваш код пестрит static и friend функциями,
которые без указания компилятору и будут повергнуты в managed.
Итак, вызов native функций очень накладен, но и здесь можно
сэкономить. Вполне очевидно, что поток вызова (когда выполняется
несколько unmanaged функций подряд) можно целиком выполнить в unmanaged
контексте. В этом случае нет взаимодействия между managed и unmanaged,
кроме выполнения одной функции, которая затем вызовет целую
последовательность функций своего контекста, при вызове которых не будет
падения производительности.
И еще одно сравнение скорости вызова функций (методов) и доступа к
членам managed и unmanaged экземпляров классов из managed контекста:
| Операция |
Managed, время, сек. |
Unmanaged, время, сек. |
| Доступ к членам (не static) |
4,41 |
~ 0 |
| Доступ к членам (static) |
34,53 |
n/a |
| Вызов метода |
0,76 |
26,00 |
Насколько видно, теория о том, что для ускорения доступа к членам
класса извне их надо делать public остается в силе.
Microsoft и сам признает, что написание враппера над unmanaged
классами является нетривиальной задачей, поэтому необходимую
производительность в .NET можно достигнуть, лишь ставя эксперименты над
различной комбинацией внешних факторов. Недаром принцип "разделяй и
властвуй" так идеально подходит к этому вопросу.

 Форум Программиста
Форум Программиста Новости
Новости Обзоры
Обзоры Магазин Программиста
Магазин Программиста Каталог ссылок
Каталог ссылок Поиск
Поиск Добавить файл
Добавить файл Обратная связь
Обратная связь 