Введение
Анализ эффективности структур данных
Любимая линейная, однородная структура данных с прямым доступом
ArrayList – неоднородный массив переменного размера
Заключение
Введение
Добро пожаловать! Вы читаете первую из шести статей в серии, посвященной
структурам данных в .NET. В этой серии статей мы будем рассматривать различные
структуры данных. Некоторые из них включены в базовую библиотеку классов .NET
Framework Base Class Library, другие мы создадим сами. Структуры данных –
это абстрактные структуры или классы, которые используются для организации
данных и предоставляют различные операции над этими данными. Наиболее
распространенной и общеизвестной структурой данных является массив
(array), который содержит непрерывную совокупность элементов данных, к
которым можно получить доступ посредством порядкового индекса.
Перед тем как углубиться в материал этой статьи, давайте взглянем на то, что
ждет нас впереди. Если вы считаете, что какие-то важные темы отсутствуют в этом
списке, автор будет рад, если вы сообщите ему о своих соображениях по адресу mitchell@4guysfromrolla.com. Автор
с удовольствием добавит ваши дополнения в соответствующий раздел или, если это
будет необходимо, напишет седьмую статью к данной серии.
В первой статье мы рассмотрим вопрос о важности структур данных и о том, как
они влияют на эффективность алгоритмов. Для определения того, как структуры
данных влияют на производительность программ, нам понадобится рассмотреть, как
мы можем строго проанализировать различные операции, выполняемые структурами
данных. В конце мы обратимся к двум структурам данным, присутствующим в .NET
Framework — Array (массив) и ArrayList (массив переменного
размера). Наверняка, вы уже использовали раньше обе эти структуры данных в
своих проектах. В первой статье мы рассмотрим операции, которые предоставляют
эти структуры данных и проанализируем эффективность этих операций.
Во второй части мы более подробно исследуем класс ArrayList
вместе с его близнецами: классами Queue (очередь) и
Stack (стек). Как и ArrayList, классы
Queue и Stack хранят непрерывную коллекцию
данных и присутствуют в базовой библиотеке классов .NET Framework. Однако, в
отличие от ArrayList, из которого мы можем получить
произвольный элемент данных, очереди и стеки позволяют получать доступ
к данным лишь в определенном последовательном порядке. Мы рассмотрим некоторые
применения очередей и стеков, и увидим, как реализовать оба эти класса, расширяя
класс ArrayList. После "возни" с очередями и стеками мы
рассмотрим хэш-таблицы, которые, как и ArrayList, предоставляют
прямой доступ к своим элементам, однако хранят данные индексированными по
строковому ключу.
В то время, как ArrayList идеально подходит для хранения
содержимого и предоставления прямого доступа к нему, он не является лучшим
выбором, когда нам необходимо осуществлять поиск среди данных. В Части 3 мы
изучим двоичное дерево поиска (binary search tree data structure), в
котором поиск можно осуществлять гораздо эффективнеe, чем в
ArrayList. В состав .NET Framework не входят встроенные классы,
реализующие двоичные деревья, так что нам придется написать свои
собственные.
Эффективность поиска по двоичному дереву зависит от порядка, в котором данные
были вставлены в дерево. Если данные вставляются в отсортированном или почти
отсортированном порядке, то выигрыш от использования двоичного дерева вместо
ArrayList значительно падает. Для обхождения этого недостатка в
Части 4 мы рассмотрим интересную рандомизированную структуру данных —
слоеный список или skip-список (SkipList). Скип-списки
обладают эффективностью поиска двоичного дерева, однако нечувствительны к
упорядоченности вводимых данных.
В Части 5 мы обратим наше внимание на структуры данных, используемые для
представления графов. Граф – это совокупность узлов (nodes) и
ребер (edges), соединяющих различные узлы. Например, мы можем
представить себе карту автодорог, как граф с городами в качестве узлов и шоссе
между городами в качестве ребер. Очень много реальных практических задач можно
абстрактно описать в терминах графов, что делает их часто используемой
структурой данных.
И наконец, в Части 6 мы взглянем на структуры данных, представляющие
множества (sets) и непересекающиеся множества (disjoint sets).
Множество – это неупорядоченная совокупность элементов. Непересекающиеся
множества – это совокупность множеств, не имеющих общих элементов. Как множества
так и неперескающиеся множества находят множество применений в программах,
которые мы детально и разберем в последней части.
Анализ эффективности структур данных
В процессе размышления над конкретным приложением или программистской задачей
многие программисты (включая меня) находят более интересным процесс написания
алгоритма для решения некоторой проблемы или добавление новой "навороченной"
функциональности в приложение с тем, чтобы сделать его более удобным для
пользователей. При этом редко, если вообще когда-либо, вы услышите восхищенные
возгласы о том, какая структура данных используется в приложении. Хотя,
правильный выбор структур данных для конкретного алгоритма может очень
значительно повлиять на его производительность. Типичный пример – это поиск
элемента в структуре данных. В случае использования обычного массива, этот
процесс занимает время пропорциональное числу элементов массива. Двоичные
деревья поиска или скип-списки, требуют сублинейного времени. При осуществлении
большого количества поисков выбор структуры данных имеет решающее значение для
скорости работы приложения, которое может быть измерено секундами, а иногда и
минутами.
А раз структура данных, используемая в алгоритме может значительно повлиять
на скорость его работы, важно иметь строгую процедуру сравнения эффективности
различных структур данных. Нас, как разработчиков, использующих структуры
данных, главным образом интересует то, как изменяется эффективность структуры
данных с ростом объема хранимой информации. А именно, как влияет добавление
каждого нового элемента, на скорость выполнения операций над данными.
Рассмотрим пример, в котором наша программа использует метод
System.IO.Directory.GetFiles(path) для получения списка всех
файлов в заданнном каталоге в виде строкового массива. Теперь, представьте, что
вам захотелось узнать, есть ли среди полученных файлов XML-файл (т.е. файл с
расширением .xml). Возможное решение – это просмотреть
последовательно весь массив и при нахождении xml-файла изменить значение
некоторого флага. Код будет выглядеть, например, так:
using System;
using System.Collections;
using System.IO;
public class MyClass
{
public static void Main()
{
string [] fs = Directory.GetFiles(@"C:\Inetpub\wwwroot");
bool foundXML = false;
int i = 0;
for (i = 0; i < fs.Length; i++)
if (String.Compare(Path.GetExtension(fs[i]), ".xml", true) == 0)
{
foundXML = true;
break;
}
if (foundXML)
Console.WriteLine("XML file found - " + fs[i]);
else
Console.WriteLine("No XML files found.");
}
}
Нетрудно заметить, что в наихудшем случае, когда XML-файл является последним
элементом или когда он вообще отсутствует, нам придется ровно 1 раз просмотреть
каждый элемент массива. Для анализа эффективности массива при сортировке мы
должны задать себе следующий вопрос: "Допустим, у нас есть массив из n
элементов. Если мы добавим один элемент в массив, так что их количество станет
равным n + 1, каково будет при этом новое время исполнения
алгоритма?". (Термин время исполнения, вопреки своему названию, не
означает абсолютное время исполнения программы в секундах, а скорее, он означает
число шагов, которое должна совершить программа для выполнения данной конкретной
задачи. При работе с массивами количеством таких шагов будет количество раз,
которое программа считывает элементы массива). Для нахождения конкретного
значения элемента массива нам потенциально придется посетить все его элементы.
Таким образом, если у нас есть n + 1 элемент, нам
потребуется выполнить n + 1 проверок. Это означает, что
время поиска в массиве линейно зависит от числа его элементов.
Тип оценок, рассматриваемых нами называется асимптотическими оценками,
поскольку мы анализируем, как эффективность структуры данных изменяется при
объме хранящихся данных, стремящемся к бесконечности. В асимптотическом анализе
обычно используют обозначение "О-большое". С помощью данного обозначения
сложность поиска в массиве можно записать, как O(n). Здесь
n – размер массива, а фраза "сложность поиска в массиве зависит от числа
его элементов как O(n)означает, что число шагов, которые требуются
для нахождения элемента массива линейно зависит от его размера. Т.е. с ростом
числа элементов массива количество шагов, необходимых для осуществления поиска
будет пропорционально размеру массива. Более систематическим методом вычисления
асимптотического времени исполнения блока кода будет следующая несложная
процедура:
- Определите действия, составляющие время исполнения алгоритма. Как уже было
упомянуто, в случае массива, рассматриваемыми действиями будут чтение и запись
элементов массива. Эти действия могут быть другими для других структур данных.
Обычно нам хочется рассматривать действия, которые несут смысл на уровне
структуры данных, а не простейшие атомарные операции, выполняемые компьютером.
Например, в фрагменте кода, приведенном выше, я вычислял время исполнения,
подсчитывая лишь то, сколько раз необходимо получать доступ к элементам массива,
не принимая во внимание время, необходимое для создания и инициализации
переменных или проверки на равенство двух строк.
- Найдите в коде строчки, в которых выполняются действия, которые вы
подсчитываете. Напишите 1 напротив каждой такой строчки.
- Для каждой строчки, рядом с которой вы написали 1, проверьте, не входит ли
она в цикл. Если да, то умножьте эту единичку на максимальное число итераций,
которое может быть выполнено в цикле. Если у вас есть несколько вложенных
циклов, умножайте последовательно на максимальное число итераций для каждого
цикла.
- Среди чисел, записанных вами отыщите максимальное. Это и будет время
исполнения.
Давайте попробуем применить этот метод к фрагменту кода, приведенному выше.
Мы уже выяснили, что действия, которые нас интересуют и которые мы будем
подсчитывать – это доступ к элементам массива. Переходя к пункту 2, замечаем что
у нас присутствуют 2 строчки в которых мы получаем доступ к элементам массива
fs — как параметр метода String.Compare() и в методе
Console.WriteLine(). Итак, ставим пометку 1 напротив каждой из этих
строк. После этого переходим к пункту 3 и замечаем, что доступ к fs
в методе String.Compare()происходит внутри цикла, которsq
исполняется максимум n раз (где n – размер массива). Итак,
зачеркиваем единичку в цикле и заменяем ее на n. В конце мы видим, что
максимальное значение - это n, а значит время исполнения блока кода можно
записать как O(n).
O(n) или линейное время – это лишь один из бесконечного числа
возможных вариантов асимптотического времени исполнения программы. Среди других
вариантов, например, O(log2 n), O(n
log2 n), O(n2),
O(2n) и так далее. Даже не углубляясь в математические дебри
асимптотического анализа, понятно, что чем меньше порядок члена в скобках
O(*), тем больше эффективность рассматриваемой структуры данных.
Например, программа, выполняющаяся за логарифмическое время O(log
n) более эффективна, чем программа, выполняющаяся за линейное время
O(n), поскольку при больших n справедливо неравенство log n
< n.
Примечание. В случае если вам необходимо краткое напоминание из
области математики, равенство loga b = y эквивалентно
ay = b. Таким образом, log2 4 = 2, т.к. 22 = 4.
Аналогично, log2 8 = 3, т.к. 23 = 8. Очевидно, что
log2 n возрастает гораздо медленнее, чем само n.
Например, когда n = 8, log2 n = 3. В Части 3 мы
рассмотрим двоичные деревья, поиск в которых осуществляется за время
O(log2 n).
В течение всей серии статей, мы будем подсчитывать время исполнения различных
операций для различных структур данных и сравнивать их друг с другом.
Любимая линейная однородная структура
данных с прямым доступом — массив
Массив – одна из простейших и наиболее широко применяемых в компьютерных
программах структур данных. В любом языке программирования массивы имеют
несколько общих свойств:
- Содержимое массива хранится в непрерывной области памяти.
- Все элементы массива имеют одинаковый тип; поэтому массивы называют
однородными (homogeneous) структурами данных.
- Существует пряммой доступ к элементам массива. (В случае других структур
данных это необязательно так. Например, в четвертой части этой серии статей
будет рассмотрена структура данных скип-список(SkipList). Для доступа к
конкретному элементу скип-списка вы должны предварительно осуществить поиск
среди других элементов скип-списка, пока не найдете требуемый элемент. В случае
с массивами, если вы хотите получить доступ к i-му элементу массива, вы
можете сделать это одной операцией: arrayName[i].)
Типичные операции для массивов включают:
- Выделение элемента(Allocation)
- Доступ к элементу (Accessing)
- Изменение размеров массива (Redimensioning)
Когда в C# объявляется массив, его значение равняется null.
Например,следующая строчка кода просто создает переменную с именем
booleanArray , которая равна null:
bool [] booleanArray;
Прежде, чем начать работу с массивом, мы должны выделить определенное
количество элементов. Синтаксически это выглядит так:
booleanArray = new bool[10];
Или более обобщенно:
arrayName = new arrayType[allocationSize];
Этой строчкой мы выделяем непрерывный блок памяти в управляемой куче
межъязыковой среды исполнения (CLR-managed heap), размер которого равен
allocationSize, умноженному на размер элемента типа
arrayType. Если arrayType – размерный тип (value
type), то создаются allocationSize распакованных (unboxed)
экземпляров типа arrayType. Если arrayType – ссылочный
тип (reference type), то создаются allocationSize ссылок на объекты
типа arrayType. (Если вы незнакомы с различиями между размерными и
ссылочными типами CLR и тем, когда переменные размещаются в управляемой куче или
стеке – ознакомьтесь со статьей Understanding
.NET's Common Type System)
Чтобы окончательно разобраться с тем, как в .NET Framework хранится
внутреннее содержимое массива, рассмотрим следующий пример:
bool [] booleanArray;
FileInfo [] files;
booleanArray = new bool[10];
files = new FileInfo[10];
Здесь, booleanArray – массив элементов размерного типа
System.Boolean, а files – это массив элементов
ссылочного типа System.IO.FileInfo. На Рисунке 1 показано состояние
управляемой кучи CLR после выполнения этих четырех строк кода.
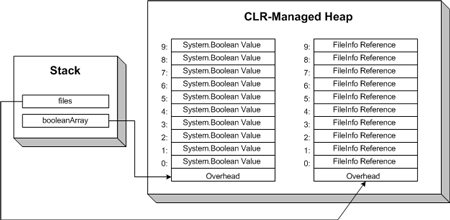
Рисунок 1. Содержимое массива выделяется в виде непрерывного блока памяти
в управляемой куче CLR
Важно помнить, что 10 элементов массива files являются ссылками
на экземпляры типа FileInfo. На Рисунке 2 эта ситуация видна
особенно четко. На нем показано содержимое памяти, если мы присвоим некоторым
элементам массива files экземпляры типа
FileInfo.
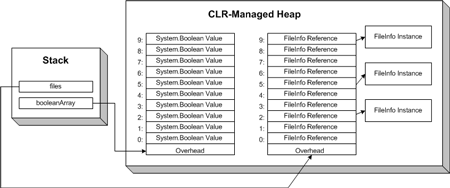
Рисунок 2. Содержимое массива располагается непрервывно в управляемой
куче.
Все массивы в .NET позволяют как считывать содержимое их элементов, так и
записывать в них. Синтаксис для доступа к элементу массива выглядит следующим
образом:
// Чтение элемента массива
bool b = booleanArray[7];
// Запись в элемент массива
booleanArray[0] = false;
Время доступа к элементу массива записывается как O(1) , т.к. оно
равно константе. Т.е. независимо от количества элементов в массиве время
чтения/записи одного элемента всегда одно и то же. Это время доступа постоянно
лишь благодаря тому, что элементы массива хранятся в памяти последовательно и
непрерывно, следовательно, для доступа к элементу массива необходимо знать лишь
адрес в памяти первого элемента массива, размер каждого элемента массива и номер
элемента, к которому необходим доступ.
Важно понимать, что в управляемом коде (managed code) нахождение элемента
массива(array lookups) происходит немного более сложным образом из-за того, что
при каждом доступе к элементу массива CLR проверяет, что запрашиваемый индекс
находится в пределах границ массива. Если указанный индекс попадает за границы
массива, то происходит исключение IndexOutOfRangeException. Такая
проверка гарантирует, что при прохождении массива мы случайно не выйдем за
пределы последнего индекса массива и не испортим данные, записанные в этой
области памяти. Стоит отметить, что эти проверки не влияют на эффективность
массива, поскольку время затрачиваемое на них не увеличивается с увеличением
размера массива.
Примечание. Такие проверки границ массива лишь немного уменьшают
производительность приложений, которые много раз осуществляют доступ к элементам
массива. Однако, с помощью объявления кода неуправляемым (unmanaged code), можно
обойти проверку границ массива. Об этом подробно написано в Главе 14 книги Дж.
Рихтера "Программирование на платформе Microsoft .NET Framework".
При работе с массивом вам может понадобиться изменить число элементов,
которое этот массив должен содержать. Для этого вам придется создать новый
экземпляр массива требуемого размера, а затем скопировать содержимое старого
массива в новый массив нового размера. Этот процесс называют изменением размера
массива (redimensioning) и его можно осуществить с помощью следующего кода:
using System;
using System.Collections;
public class MyClass
{
public static void Main()
{
// создание массива целых чисел из 3 элементов
int [] fib = new int[3];
fib[0] = 1;
fib[1] = 1;
fib[2] = 2;
// Изменение размера до 10 элементов
int [] temp = new int[10];
// Копирование массива fib в temp
fib.CopyTo(temp, 0);
// Присвоим массиву temp значение fib
fib = temp;
}
}
После выполнения последней строчки кода, fib ссылается на массив
из 10 элементов типа Int32. Элементы с 3-го по 9-й в массиве fib
будут иметь значение по умолчанию для типа Int32 – 0.
Массивы являются превосходной структурой данных, если мы хотим хранить
коллекцию однородных типов, к которым мы хотим иметь прямой доступ. Поиск в
неотсортированном массиве занимает линейное от размера массива время. Это
приемлемо, если мы работаем с маленькими массивами,или когда нам нужно лишь
изредка производить поиск внутри массива. Если же ваше приложение хранит большие
массивы, в которых часто производится поиск, то существуют структуры данных
гораздо лучше приспособленные к таким ситуациям. Мы рассмотрим некоторые из них
в следующих статьях этой серии. (Помните, что если вы производите поиск в
массиве по некоторому ключу, а массив отсортирован по этому ключу, вы
всегда можете использовать алгоритм двоичного поиска, сложность которого
O(log n) , что эквивалентно времени поиска в двоичных деревьях. На
самом деле, класс Array содержит статический метод BinarySearch().
Более подробно этот метод описан в более ранней статье автора Efficiently
Searching a Sorted Array.
Примечание .NET Framework поддерживает также и многомерные массивы.
Многомерные массивы, как и одномерные требуют постоянного времени для
доступа к своим элементам. Вспомните, что время поиска в n-элементном массиве
равно O(n). Для двумерного массива размером nxn
время поиска будет равно O(n2), потому что процедура поиска должна
будет просмотреть n2 элементов. В более общем случае, время поиска в
k-мерном массиве есть O(nk).
ArrayList – неоднородный массив
переменного размера
Несмотря на то, что обычные массивы, безусловно, находят широкое применение,
они накладывают определенные ограничения на программиста, поскольку каждый
массив может хранить данные только одного типа (однородность) и вдобавок перед
использованием массива вы должны выделить (allocate) определенное количество
элементов. Однако, часто разработчикам хочется чего-то более гибкого — простую
коллекцию объектов потенциально разного типа, с которыми можно было бы просто
работать, не беспокоясь о вопросах, связанных с выделением
элементов(allocation). Базовая библиотека классов .NET Framework содержит такую
структуру данных. Она называется System.Collections.ArrayList.
В кусочке кода, приведенном ниже, демонстрируется ArrayList в действии.
Заметьте, что если мы используем ArrayList, то мы можем добавить в него любой
тип, причем никаких действий по выделению памяти выполнять не требуется. На деле
получается, что в ArrayList могут быть добавлены элементы любого типа. Более
того, нам больше не нужно заботиться об изменении размера ArrayList. Все эти
действия производятся для нас за кулисами.
ArrayList countDown = new ArrayList();
countDown.Add(5);
countDown.Add(4);
countDown.Add(3);
countDown.Add(2);
countDown.Add(1);
countDown.Add("blast off!");
countDown.Add(new ArrayList());
А за кулисами ArrayList использует System.Array типа
object. Поскольку все типы являются прямыми или непрямыми
наследниками object, массив экземпляров типа object
может содержать элементы произвольного типа. По умолчанию ArrayList создает
массив из 16 элементов типа object, хотя точный размер может быть
указан через параметр конструктора в свойстве Capacity. При добавлении
элемента с помощью метода Add() число элементов во внутреннем массиве
сверяется с размером массива. Если операция добавления элемента вызывает
превышение числа элементов массива над его размером, то размер автоматически
удваивается(redimensioned).
ArrayList, как и обычный массив, использует индекс для доступа к своим
элементам с помощью аналогичного синтаксиса:
// чтение элемента
int x = (int) countDown[0];
string y = (string) countDown[5];
// запись данных
countDown[1] = 5;
// ** БУДЕТ СГЕНЕРИРОВАНО ИСКЛЮЧЕНИЕ ArgumentOutOfRange **
countDown[7] = 5;
Поскольку ArrayList хранит массив объектов, вы должны явным образом привести
(explicitly cast) считанное из ArrayList значение к тому типу данных, который
хранился в данном элементе ArrayList-а. Также заметьте, что если вы попытаетесь
сослаться на элемент ArrayList-а номер, которого больше, чем размер ArrayList-а,
будет сгенерировано исключение System.ArgumentOutOfRange.
Хотя ArrayList обеспечивает дополнительную гибкость по сравнению с обычным
массивом, достигается эта гибкость за счет скорости работы, особенно если вы
храните в ArrayList-е размерные типы (value types). Вспомните, что массив
размерных типов — таких как System.Int32,
System.Double, System.Boolean, и т.д. — хранится в
непрерывной области памяти управляемой кучи в распакованной форме (unboxed
form). Внутренний массив ArrayList-а при этом является массивом ссылок на
экземпляры типа object. Поэтому, даже если ваш ArrayList не хранит ничего, кроме
размерных типов, каждый элемент ArrayList-а является ссылкой на упакованный
размерный тип (boxed value type), как показано на Рисунке 3.
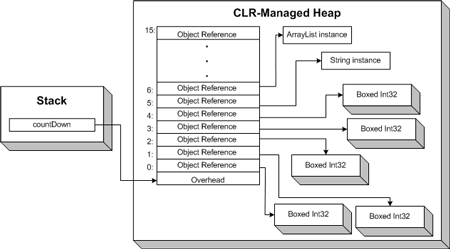
Рисунок 3. ArrayList содержит непрерывную область ссылок на экземпляры
типа object
Процессы упаковки и распаковки, наряду с наличием дополнительных накладных
расходов при хранении размерных типов в ArrayList-е, могут негативно сказаться
на производительности вашего приложения при использовании больших ArrayList-ов с
большим количеством операций чтения/записи. Как показывает Рисунок 3,
использование памяти для ссылочных типов выглядит одинаково как в случае
использования обычных массивов, так и ArrayLists-ов.
Автоматическое изменение размера ArrayList-а не должно вызывать ухудшения
производительности по сравнению с массивом. Если вам известно точно число
элементов, которое должно храниться в ArrayList-е, вы просто можете отключить
автоматическое изменение размера, указав начальный размер в конструкторе
ArrayList-а. Если точный размер вам неизестен, даже в случае использования
массива, вам понадобиться увеличивать его размер, если число вставляемых
элементов превышает размер массива.
Классической задачей computer science является определение того, сколько
места необходимо выделять при окончании памяти в некотором буфере (области
памяти). Одно решение соcтоит в том, чтобы дополнительно выделить только один
элемент из памяти буфера. Т.е. при добавлении элемента в заполненный массив из 5
элементов, размер массива станет равным шести. Очевидно, что данный подход
является наиболее экономным, однако он может быть слишком дорогостоящим, потому
что за каждой вставкой нового элемента после заполнения массива следует
изменение его размера.
Диаметрально противоположный подход состоит в увеличении размера массива в
100 раз при окончании наличия свободного места в нем для вставки новых
элементов. Т.е. после заполнения массива из 5 элементов при попытке добавления
6-го элемента размер массива будет изменен до 500 элементов. Ясно, что такой
подход грандиозно уменьшает число изменений размера массива, однако если лишь
немного элементов будут добавлены в массив, огромное количество свободной памяти
будет потрачено впустую.
Проверенным на практике компромиссом решения данной проблемы является простое
удвоение текущего размера массива, когда кончается свободное место для новых
элементов. Т.е. для массива, в котором было изначально выделено 5 элементов,
добавление шестого элемента вызовет увеличение размера массива до 10 элементов.
Это как раз и делает класс ArrayList и, что самое приятное, он делает все
это за вас.
Асимптотическое время исполнения операции ArrayList-а такое же, как и у
обычного массива. Несмотря на то, что при работе с ArrayList-ом действительно
возникают дополнительные накладные расходы, особенно при хранении размерных
типов, соотношение между числом элементов ArrayList-а и стоимостью выполнения
операций не отличается от стандартного массива.
Заключение
Данная статья открыла обсуждение структур данных, фокусируясь на том, почему
изучение струтур данных важно. Были описаны способы анализа эффективности
использования структур данных. Этот материал важен для подсчета времени
исполнения различных операций структур данных и является полезным инструментом
при выборе той или иной структуры данных для конкретной программистской
задачи.
После изучения того, как следует анализировать структуры данных, мы
обратились к исследованию двух наиболее распространенных структур данных в
базовой библиотеке классов .NET Framework — классам System.Array и
System.Collections.ArrayList. Массивы позволяют хранить непрерывный блок
однородных типов. Основное их преимущество состоит в исключительно малом времени
доступа к своим элементам для чтения и записи. Слабое место массивов –
дороговизна поиска в них, т.к. при поиске в неотсортированном массиве мы
потенциально должны посетить каждый элемент массива.
ArrayList является более гибкой массивоподобной структурой данных. Он может
содержать данные различных типов, используя массив object-ов. Более
того, ArrayList не требует явного выделения элементов и может самостоятельно
расширяться по мере добавления элементов.
В следующей статье нашей серии мы обратим внимание на классы Stack и
Queue. Мы также рассмотрим ассоциативные массивы (associative arrays),
которые представляют собой массивы, элементы которых индексируются не
целочисленным, а строковым значением. Ассоциативные массивы присутствуют в
базовой библиотеке классов .NET Framework в виде класса Hashtable.
Перевод — Станислав Воног, Московский физико-технический институт

 Форум Программиста
Форум Программиста Новости
Новости Обзоры
Обзоры Магазин Программиста
Магазин Программиста Каталог ссылок
Каталог ссылок Поиск
Поиск Добавить файл
Добавить файл Обратная связь
Обратная связь 