Введение
Прошло меньше недели с момента
написания предыдущей статьи. Но как
показывает статистика, интерес у наших
посетителей к тому, что было сделано -
есть. И это естественно вдохновляет меня
на продолжение публикаций по данному
разделу.
Итак, к делу. В данной публикации мы
рассмотрим то, что идеально подходит под
поговорку «все новое, это хорошо забытое
старое». В данном случае нельзя сказать,
что DataReader это хорошо забытое старое.
Скорее даже наоборот – это то, чем
активно оперировали в предыдущей
технологии доступа к данным ADO (Ole Db) и то,
что очень удобно вписалось в абсолютно
новую идеологию доступа к данным такую
как ADO.NET.
В настоящей технологии, такой как ADO.NET
RecordSet в таком виде, в каком он
существовал в Ado, уже не существует. Его
заменили такие объекты как Data и DataReader. Но
идея работы с «однонаправленным» и
последовательным набором данных
остается и очень активно применяется в
настоящий момент.
На самом деле, можно во многом
сопоставить объекты DataTable и RecordSet. DataTable в
ADO.NET, это тот же слепок данных.
Возможность манипулирования данными в «отключенном»
режиме, возможность отката к
первоначальным данным. DataReader это аналог
того же RecordSet, но в «подключенном» режиме
и он, как и RecordSet повторяет все его
основные свойства: однонаправленный
доступ, только для чтения, что дает нам
очень быструю загрузку потока данных.
Данный метод загрузки идеально
подходит для реализации статических
справочников, при этом задействовав
минимум ресурсов системы.
В системе ADO.NET объекты DataReader-ы
представлены двумя классами SqlDataReader и
OleDbDataReader – находящимися соответственно
в неймспейсах System.Data.SqlClient и System.Data.OleDb.
Составные части DataReader.
Давайте подробнее пройдемся по
организации DataReader.
Как такового базового класса для DataReader
не существует. Он реализует два
интерфейса IDataReader и IDataRecord.
IDataReader содержит четыре метода и три
свойства.
Методы:
|
Close
|
Закрывает объект
|
|
GetShemaTable
|
Возвращает описание схемы DataTable
согласно результирующего набора
данных
|
|
NextResult
|
Движение datareader к следущему
результирующему набору если он
присутсвует
|
|
Read
|
Движение datareader к следующей записи.
|
а также свойства:
|
Depth
|
Значение, показывающее глубину
вложенности для текущей строки.
Находясь в обоих типах Reader-ов
применимо только в OleDbDataReader.
|
|
IsClosed
|
Возвращает логическую величину
показывающую закрыт datareader или нет.
|
|
RecordsAffected
|
Получает количество записей
которые попадают под действие SQL
запроса. Значение -1 показывает что
запрос полностью выполнен.
|
IDataRecord поддерживает методы
отображения значений колонок и два
свойства:
Методы:
|
GetXXX (GetBoolean, GetByte)
|
Эти методы позволяют получить
значения соответствующих типов
колонок.
|
Свойства
|
FieldCount
|
Позволяет получить значение числа
колонок в текущей строке
|
|
Item
|
Позволяет получить значение
колонки.
|
Итак, если посмотреть на эти два
интерфейса, то можно понять, что в
принципе это и есть тот самый
краеугольный камень DataReader как объекта,
который дает наименьшее, что нужно для
потребностей программиста в быстром
потоке считанных данных.
Теперь хочется перейти
непосредственно к DataReader.
Я бы хотел подчеркнуть еще один очень
важный момент в двух различных объектах
в ADO.NET для методов доступа Sql и Ole DB, а
именно это скорость доступа к данным. В
форумах часто возникают споры на тему
того, что лучше использовать. Я думаю,
что это объяснение несколько прояснит
картину происходящего.
Чуть ниже я приведу результаты
тестирования данных объектов, но сейчас
давайте посмотрим на схему организации
этих объектов, для того чтобы не
относиться предвзято к результатам
теста на быстродействие.
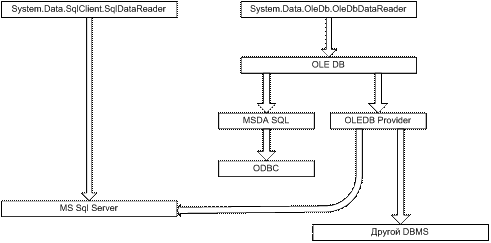
Данная схема, я надеюсь, проясняет
алгоритм доступа к данным. И забегая
чуть вперед, скажу, что схема и позволяет
понять, почему доступ к Sql Server происходит
намного медленней через Ole Db чем через Sql.
SqlDataReader использует SQL Server’s Tabular Data Stream (TDS)
протокол, т.е. «родной» канал передачи
данных. А если взглянуть на OleDbDataReader, то
мы видим, что в механизме доступа
задействованы еще несколько слоев,
которые естественно уменьшают скорость
доступа к данным Sql Server.
Скорость считывания - одно из основных
качеств DataReader.
Сейчас я приведу несколько
статистических примеров по
быстродействию доступа к данным для
различных типов DataReader.
Давайте будем подходить к вопросу
профессионально, и оценим основной
параметр DataReader-ов.
Первый анализ покажет нам влияние
способа чтения колонки с данными по
имени и порядковому номеру на скорость.
Да-да, вы не ошиблись, именно так. И
разница в способе доступа весьма
заметна. Давайте взглянем на результаты
тестов.
Имеем следующие два вызова:
object name = reader ["ID"];
object name = reader [0];
В первом случае это колонка с
идентификатором ID, во втором порядковый
номер колонки. Вот что нам дают
результаты тестирования на 10 миллионах
записей:
| Sql |
reader["ID"] |
64.192304 сек. |
| reader[0] |
48,399595 сек. |
| OleDb |
reader["ID"] |
152,5092 сек. |
| reader[0] |
131,12855 сек. |
Этот замечательный тест широко
открывает нам глаза на, казалось бы,
незаметный факт: способ обращения к
колонке для получения данных. Так же вы
видите, насколько отличаются скорости
между экземплярами объектов Sql и OleDb. И
теперь вас этот факт уже не удивляет.
Не знаю, почему, возможно из-за своей
любопытности, а возможно из-за сомнений
своих друзей :), я решил написать
тестовый код для сравнения на практике
этих показателей, и я Вам скажу не зря. Я
обнаружил еще более интересные
результаты.
Итак, как говорится код в студию :).
Для начала приведу код на T-SQL для
вставки нужного числа записей:
SET NOCOUNT ON
use TestForDataReader
drop table t
CREATE TABLE t(
ItemID int IDENTITY(1,1),
ForumID int DEFAULT 1 NOT NULL,
ParentItemID int DEFAULT 1 NULL,
ThreadID int DEFAULT 1 NOT NULL,
UserID int DEFAULT 1 NULL,
postDate smalldatetime DEFAULT '2001-01-01' NOT NULL,
Subject varchar(255) DEFAULT ('Anonymous') NOT NULL,
NameUser varchar(50) DEFAULT ('Anonymous') NOT NULL,
EmailUser varchar(100) DEFAULT ('Anonymous') NULL,
X int DEFAULT 1 NOT NULL,
[level] smallint DEFAULT (0) NOT NULL,
sendEmail bit DEFAULT (0) NOT NULL
)
declare @@countRec int, @@leftRec int, @@allRec int
set @@countRec = 0
Set @@allRec = 5000000 /* Количество записей для вставки в таблицу */
insert t default values
while(@@countRec < @@allRec)
begin
insert t
select
ForumID ,
ParentItemID ,
ThreadID ,
UserID ,
postDate ,
Subject ,
NameUser ,
EmailUser ,
X ,
[level] ,
sendEmail
from t
Set @@countRec = (select count(*) from t)
if(@@countRec*2 > @@allRec)
begin
set @@leftRec = @@allRec - @@countRec
SET ROWCOUNT @@leftRec
end
end
SET NOCOUNT OFF
select count(*) from t
Здесь применен метод инкрементальной
вставки, но даже такой метод потребовал
от моей системы значительных ресурсов.
Вставка 5 миллионов записей по такому
алгоритму занял у меня около 35 минут.
Самое время упомянуть о параметрах
системы: Pentium III, 450 mHz, 256 mB RAM, Win 2000, MS SQL 2000, .Net
Framework Final (без сервис пака), VS.Net Final Release.
Проект, который использовался при
тестировании, доступен для загрузки здесь.
Вот фрагмент кода, который
иллюстрирует механизм доступа,
примененный в данном проекте:
static void testSql(int iField, string strField, string Select)
{
SqlConnection sqlConnection = new SqlConnection();
SqlCommand sqlSelectCommand = new SqlCommand();
sqlConnection.ConnectionString = "data source=.;initial catalog=TestForDataReader;integrated security=SSPI;" +
"persist security info=False;workstation id=;packet size=4096";
sqlSelectCommand.CommandText = Select;
sqlSelectCommand.Connection = sqlConnection;
sqlSelectCommand.CommandTimeout = 900;
sqlConnection.Open();
SqlDataReader reader = sqlSelectCommand.ExecuteReader();
long startTime = DateTime.Now.Ticks;
object values;
while(reader.Read())
{
values = reader[iField];
}
long endTime = DateTime.Now.Ticks;
reader.Close();
TimeSpan timeTaken1 = new TimeSpan(endTime - startTime);
reader = sqlSelectCommand.ExecuteReader();
startTime = DateTime.Now.Ticks;
while(reader.Read())
{
values = reader[strField];
}
endTime = DateTime.Now.Ticks;
reader.Close();
TimeSpan timeTaken2 = new TimeSpan(endTime - startTime);
sqlConnection.Close();
Console.WriteLine("{0} и {1} секунд; ", timeTaken1.TotalSeconds.ToString(), timeTaken2.TotalSeconds.ToString());
}
Вот реальные результаты теста на 5
миллионах записей:
D:\work\Visual Studio Projects\dr_test\bin\Debug>TestDR 0 ItemID
"Select ItemID from t"
Test производительности для DataReader. Written by Serg Vorontsov
Доступ к Sql объектам:
по индексу колонки reader[0] и по имени колонки reader[ItemID]:
23.2434224 и 31.6555184 секунд;
Доступ к OleDb объектам:
по индексу колонки reader[0] и по имени колонки reader[ItemID]:
83.7504272 и 105.501704 секунд;
D:\work\Visual Studio Projects\dr_test\bin\Debug>TestDR 0 ItemID
"Select ItemID, ParentItemID, ForumID, ThreadID from t"
Test производительности для DataReader. Written by Serg Vorontsov
Доступ к Sql объектам:
по индексу колонки reader[0] и по имени колонки reader[ItemID]:
44.5440512 и 52.9461328 секунд;
Доступ к OleDb объектам:
по индексу колонки reader[0] и по имени колонки reader[ItemID]:
108.7263408 и 129.8767536 секунд;
D:\work\Visual Studio Projects\dr_test\bin\Debug>TestDR 0 ItemID "Select * from t"
Test производительности для DataReader. Written by Serg Vorontsov
Доступ к Sql объектам:
по индексу колонки reader[0] и по имени колонки reader[ItemID]:
123.1470768 и 148.9642 секунд;
Доступ к OleDb объектам:
по индексу колонки reader[0] и по имени колонки reader[ItemID]:
269.6978064 и 306.540784 секунд;
Вот это да! Что мы видим? А видим мы то,
что документация нас не обманула – но
скорость еще более разительно зависит
от количества запрашиваемых колонок в
запросе – и вы можете оценить насколько
сильно! Объясняется это алгоритмом
доступа к элементу колонки. Гуннерсон
приводит алгоритм простого
циклического перебора, в Microsoft для этого
применили алгоритм рекурсивного вызова,
а мы имеем на это свой, так сказать, «взгляд»
- но это уже, как говорится, другая
история :).
Вот как полезно проводить
практические исследования. Я
предоставляю вам полный код для
дальнейших экспериментов. Если вы,
обнаружите, что-либо еще, о чем я не
упомянул в данном тесте – милости
просим: форум в вашем распоряжении :)
Давайте еще двинемся дальше чуть
дальше и профессиональнее, так сказать «продвинем»
наши познания в быстродействии
считывания данных. А именно: типо-безопасных
и типо-НЕ-безопасных способов доступа.
| Sql |
reader.GetString(1) |
65.7545504 сек. |
| reader.GetSqlString(1) |
65,6844496 сек. |
| (string)reader[1] |
46,81732 сек. |
| OleDb |
reader.GetString(1) |
140,1114704 сек. |
| (string)reader[1] |
147,061464 сек. |
Эти примеры отлично иллюстрирует
скорость доступа при помощи индексатора.
Что выбирать? Естественно решать Вам. Я
лишь привел статистические данные. Я не
тестировал данные, приведенные в
последней таблице, которые я получил из
документации, но предыдущие тесты
показали, что я могу им доверять.
Программисты из Microsoft предоставили нам
богатейшие возможности по обработке
данных, что позволяет нам быть гибкими в
своих решениях.
Практика.
И все-таки, я еще чуть-чуть Вас «помучаю»
описанием прежде, чем мы перейдем к
конкретным практическим действиям. :)
Давайте посмотрим на алгоритм работы
DataReader.
Прежде, чем мы заполним DataReader данными,
мы должны будем создать экземпляры
некоторых объектов, а именно Connection и Command.
Сейчас я приведу Вам практически
основной шаблон кода по созданию и
заполнению DataReader-a.
Я предлагаю взять за основу Ole Db
алгоритм доступа ввиду того, что в
предыдущей статье мы использовали
объекты типа Sql.
Вот основной алгоритм:
OleDbConnection conn = new OleDbConnection("Provider=SQLOLEDB;Data Source=localhost;" +
"Initial Catalog=Nothwind;Integrated Security=SSPI;");
OleDbCommand command = new OleDbCommand(“select * from customers”, conn);
conn.Open();
OleDbDataReader reader = command.ExecuteReader();
while( reader.Read() )
{
// Ваш код управления
}
reader.Close();
conn.Close()
Все гениальное просто! Главное не
забыть закрыть DataReader и Connection после
выполнения!!! И чем скорей, тем лучше ?.
Почему? Потому, что как говорится, везде
есть свои положительные и отрицательные
стороны. DataReader может использовать Connection
только в монопольном режиме. А это
значит, что если вы захотите
использовать один и тот же Connection для
нескольких DataReader-ов то у Вас ничего не
получится. Вам надо будет создавать
несколько объектов Connection.
Вы можете оценить, насколько просто
использовать DataReader. И какие
преимущества в быстродействии он дает
при заполнении простых структур! Чуть
ниже мы проведем практические действия
с нашим примером. А сейчас я хотел бы еще
обратить Ваше внимание на аргументы
вызова ExecuteReader метода:
| CloseConnection |
Закрыть соединение при
закрытии датаридера |
| KeyInfo |
Запрос вернет колонку и
информацию о первичном ключе. |
| ShemaOnly |
Запрос вернет
исключительно информацию о схеме
колонок |
| SequentialAccess |
Полученные данные будут
как результат последовательного
чтения колонок |
| SingleResult |
Запрос вернет единичный
результат |
| SingleRow |
Запрос вернет одну строку |
Формат подачи параметров для ExecuteReader
такой:
OleDbDataReader reader = command.ExecuteReader
(CommandBehavior.CloseConnection | CommandBehavior.SingleResult)
Итак, вот оно самое интересное. Я пока ума не приложу, что мы можем
написать за приложение на основе того
материала, который у нас был рассмотрен
в предыдущей публикации, потому мы пока
не будем задаваться написанием, какого
либо определенного приложения. Давайте
будем использовать данный проект как «площадку
для гольфа» т.е. пока мы не приобретем
достаточных знаний, для того чтобы
сделать, что-либо осмысленное. Да и к
тому же, гораздо проще ориентироваться в
не перегруженном коде, а значит – да
здравствует дизайнер и клавиша Delete! :)
Откроем наш проект и посмотрим на то,
что мы имеем. А имеем мы динамически
созданный грид и типизированный датасет.
А в окне дизайнера чисто – даже и
удалить то нечего. :) Но не будем
расстраиваться, а поближе глянем на наш
код.
Я предлагаю сделать несколько
примеров, которые практически полностью
иллюстрируют основные возможности
работы с DataReader.
Первый пример я предлагаю сделать на
основе нашего DataGrid и получить схему
таблицы. Для этого внесем следующие
изменения в наш код:
#region Personal init componets
///
/// Personal init componets
///
private void InitComponent()
{
sqlBuild = new SqlCommandBuilder(sqlDataAdapter);
myDataGrid = new DataGrid();
// myDataGrid.DataSource = myDataSet;
myDataGrid.Location = new System.Drawing.Point(0, 8);
myDataGrid.Size = new System.Drawing.Size(536, 272);
myDataGrid.Dock = DockStyle.Fill;
this.Controls.AddRange(new System.Windows.Forms.Control[] {
this.myDataGrid});
// sqlDataAdapter.Fill(myDataSet);
sqlConnection.Open();
SqlDataReader reader = sqlSelectCommand.ExecuteReader(
System.Data.CommandBehavior.SchemaOnly);
myDataGrid.SetDataBinding(reader.GetSchemaTable(), "");
reader.Close();
sqlConnection.Close();
//**********************************************
}
#endregion Personal init componets
Итак этот код показывает нам насколько
прост и удобен в использовании DataReader. В
результате компиляции и выполнения
данного кода мы увидим заполненный
схемой грид.
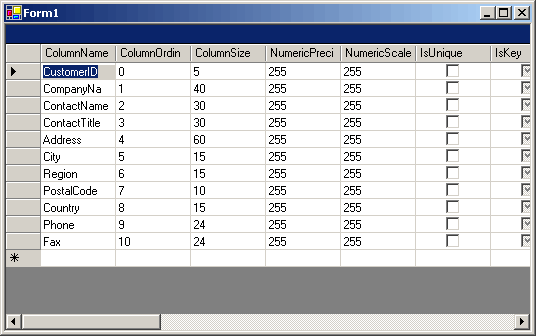
Добавленная строка:
myDataGrid.Dock = DockStyle.Fill;
позволяет нам более удобно отображать
грид на форме. Возможно это не совсем
удачная таблица для иллюстрации схемы
таблицы, потому что практически все
колонки у нее типа System.String, но я думаю,
что вы в состоянии теперь проделать
такой же эксперимент и с другими
таблицами. Для этого нужно всего лишь
изменить строку запроса в экземпляре
Command.
Идем дальше. Следующий пример покажет
нам, каким образом мы можем заполнять
объект, ну скажем, ListView данными из
таблицы. Опять вносим изменения в код:
public class Form1 : System.Windows.Forms.Form
{
...
private DataGrid myDataGrid;
///
/// Экземпляр ListView для экспериментов
///
private ListView lv;
...
далее (будьте внимательны - были
сделаны удаления некоторых строк) :
#region Personal init componets
///
/// Personal init componets
///
private void InitComponent()
{
sqlBuild = new SqlCommandBuilder(sqlDataAdapter);
this.lv = new ListView();
lv.Location = new System.Drawing.Point(0, 8);
lv.Size = new System.Drawing.Size(530, 272);
lv.View = System.Windows.Forms.View.Details;
lv.Dock = DockStyle.Fill;
this.Controls.AddRange(new System.Windows.Forms.Control[] {
this.lv});
lv.Columns.Add("CustomerID", -2, HorizontalAlignment.Left);
lv.Columns.Add("CompanyName", -2, HorizontalAlignment.Left);
lv.Columns.Add("ContactName", -2, HorizontalAlignment.Left);
lv.Columns.Add("ContactTitle", -2, HorizontalAlignment.Left);
lv.Columns.Add("Address", -2, HorizontalAlignment.Left);
lv.Columns.Add("City", -2, HorizontalAlignment.Left);
lv.Columns.Add("Region", -2, HorizontalAlignment.Left);
lv.Columns.Add("PostalCode", -2, HorizontalAlignment.Left);
lv.Columns.Add("Country", -2, HorizontalAlignment.Left);
lv.Columns.Add("Phone", -2, HorizontalAlignment.Left);
lv.Columns.Add("Fax", -2, HorizontalAlignment.Left);
sqlConnection.Open();
SqlDataReader reader = sqlSelectCommand.ExecuteReader();
while(reader.Read())
{
object[] values = new object[ reader.FieldCount];
reader.GetValues( values);
ListViewItem item = new ListViewItem(((object)values[0]).ToString());
for(int i = 1; i < reader.FieldCount; i++)
item.SubItems.Add(((object)values[i]).ToString());
lv.Items.Add(item);
}
reader.Close();
sqlConnection.Close();
/*
myDataGrid = new DataGrid();
// myDataGrid.DataSource = myDataSet;
myDataGrid.Location = new System.Drawing.Point(0, 8);
myDataGrid.Size = new System.Drawing.Size(536, 272);
myDataGrid.Dock = DockStyle.Fill;
this.Controls.AddRange(new System.Windows.Forms.Control[] {
this.myDataGrid});
// sqlDataAdapter.Fill(myDataSet);
*/
//**********************************************
}
#endregion Personal init componets
В результате чего мы получим следующий
результат:
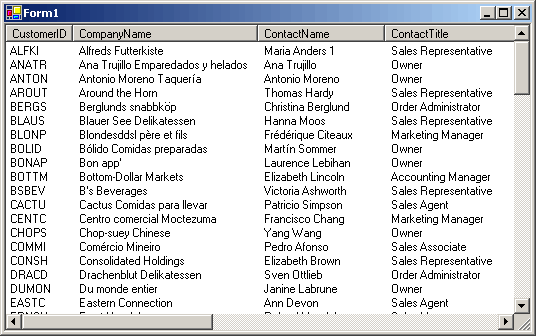
Но давайте будем профессионалами, и не
будем губить основное достоинство
DataReader-а - скорость.
Как вы понимаете, цикл, в момент чтения
строк, естественно сводит на нет
скорость считывания данных.
Я предлагаю вам для организации
хранения данных использовать такой
объект как ArrayList. Это не помешает также
для Вашей практики работы с массивами
данных. Тем более что нет более быстрого
способа оперирования данными, чем
память.
Итак, опять «прошерстим» наш код:
#region Personal init componets
///
/// Personal init componets
///
private void InitComponent()
{
sqlBuild = new SqlCommandBuilder(sqlDataAdapter);
ArrayList rowList = new ArrayList();
this.lv = new ListView();
sqlConnection.Open();
SqlDataReader reader = sqlSelectCommand.ExecuteReader();
while(reader.Read())
{
object[] values = new object[ reader.FieldCount];
reader.GetValues( values);
rowList.Add( values);
}
reader.Close();
sqlConnection.Close();
lv.Location = new System.Drawing.Point(0, 8);
lv.Size = new System.Drawing.Size(530, 272);
lv.View = System.Windows.Forms.View.Details;
lv.Dock = DockStyle.Fill;
this.Controls.AddRange(new System.Windows.Forms.Control[] {
this.lv});
lv.Columns.Add("CustomerID", -2, HorizontalAlignment.Left);
lv.Columns.Add("CompanyName", -2, HorizontalAlignment.Left);
lv.Columns.Add("ContactName", -2, HorizontalAlignment.Left);
lv.Columns.Add("ContactTitle", -2, HorizontalAlignment.Left);
lv.Columns.Add("Address", -2, HorizontalAlignment.Left);
lv.Columns.Add("City", -2, HorizontalAlignment.Left);
lv.Columns.Add("Region", -2, HorizontalAlignment.Left);
lv.Columns.Add("PostalCode", -2, HorizontalAlignment.Left);
lv.Columns.Add("Country", -2, HorizontalAlignment.Left);
lv.Columns.Add("Phone", -2, HorizontalAlignment.Left);
lv.Columns.Add("Fax", -2, HorizontalAlignment.Left);
foreach( object[] row in rowList)
{
ListViewItem item = new ListViewItem(row[0].ToString());
int i =0;
foreach( object column in row)
{
if(i > 0)
item.SubItems.Add(column.ToString());
i++;
}
lv.Items.Add(item);
}
/*
myDataGrid = new DataGrid();
// myDataGrid.DataSource = myDataSet;
myDataGrid.Location = new System.Drawing.Point(0, 8);
myDataGrid.Size = new System.Drawing.Size(536, 272);
myDataGrid.Dock = DockStyle.Fill;
this.Controls.AddRange(new System.Windows.Forms.Control[] {
this.myDataGrid});
// sqlDataAdapter.Fill(myDataSet);
*/
//**********************************************
}
#endregion Personal init componets
Я специально повторил практически
весь код InitComponent() потому, что я
переставил блоки для более удобного
чтения кода. Я советовал бы Вам
внимательно просмотреть код.
Здесь вы увидите, что чтение DataReader
максимально оптимизировано, как по
скорости чтения, так и по скорости
открытия закрытия соединения и самого
DataReader.
Надеюсь, что вы сегодня приятно
провели время, манипулируя с таким
замечательным объектом как DataReader. Я
очень надеюсь, что я предоставил вам
максимум информации для дальнейшей
работы с ним.
Дальнейшие публикации будут посвящены
Типизированным датасет в ADO.NET. Я не
случайно написал с большой буквы. Это
колоссальный объем в настоящей
технологии доступа к данным, которым вы
будете манипулировать ежедневно. Если у
вас возникли вопросы, я с большим
удовольствием отвечу Вам на них, на
страницах нашего форума.

 Форум Программиста
Форум Программиста Новости
Новости Обзоры
Обзоры Магазин Программиста
Магазин Программиста Каталог ссылок
Каталог ссылок Поиск
Поиск Добавить файл
Добавить файл Обратная связь
Обратная связь 