Введение
Варианты архитектуры для доступа к данным влияют на
производительность, масштабируемость, надежность и применимость. В этой
статье подробно рассматриваются аспекты производительности при
использовании этих вариантов путем сравнения относительной
производительности различных методов доступа к данным, таких как
Microsoft® ADO.NET Command, DataReader, DataSet и XML Reader, в общих
сценариях приложения с базой данных Microsoft SQL Server™ 2000. При этом
ссылочный набор методов сравнивается со ссылочным набором данных
Customer, Order и OrderDetail (клиент, заказ, подробные сведения о
заказе) при разном числе пользователей.
Примеры кода, иллюстрирующие сравниваемые здесь методы, содержатся в
статьях на смежную тему, в которых обсуждаются
Методы доступа к данным ADO.NET. В этих примерах рассматривается
доступ к отдельному значению, отдельной строке, нескольким строкам и
иерархическим данным с использованием ADO.NET.
Сценарии тестирования
Производительность любой операции данных зависит от ряда факторов.
Конструкция объектов, используемых для доступа к данным, и
совокупность этих объектов налагает различный объем издержек. В
частности, объем издержек, связанных с реализацией и заполнением
объектов ADO.NET DataSet, больше объема издержек, связанных с
реализацией объектов ADO.NET DataReader или XMLReader.
Методы доступа к данным отличаются по нагрузке на базу данных. В
частности, методы доступа DataSet и DataReader по-разному
используют подключение к базе данных при чтении данных приложением.
Методы доступа к данным, использующие хранимые процедуры, позволяют
уменьшить нагрузку на базу данных по сравнению с подходами,
использующими динамические выражения SQL. Точно так же ресурсы сервера
используются при преобразовании реляционных данных в XML и из XML.
Число циклов обработки на сервере базы данных также является важным
фактором, особенно при охвате блокировками и транзакциями нескольких
циклов обработки. Другим фактором является объем посылаемых по сети
данных, если данные в формате XML больше сопоставимых данных в других
форматах.
Для сравнения вариантов доступа к данным ADO.NET использовались
типичные для бизнес-приложений операции, такие как получение строки
клиента, получение заказов клиента и вставка заказа. Для того чтобы тест
был максимально реалистичным, в базу данных было загружено более 100000
строк учетных записей клиентов, один миллион строк заказов (10 заказов
на одного клиента) и более пяти миллионов строк подробных сведений о
заказе (5 строк подробных сведений на один заказ). Данные находятся в
базе данных SQL Server 2000, для подключения к SQL Server используется
провайдер данных SQL Server .NET. Некоторые из сравниваемых здесь
подходов используют возможности XML SQL Server 2000.
Для сравнения методов доступа к данным использовались описанные ниже
методы.
GetOrderStatus
С помощью метода GetOrderStatus принимается OrderId
(Идентификатор заказа) и возвращается целое число, представляющее статус
заказа.
GetCustomer
С помощью метода GetCustomer принимается CustomerId
(Идентификатор клиента) и возвращается отдельная строка, содержащая
информацию о клиенте.
GetCustomers
С помощью метода GetCustomers принимается CustomerId и
параметр, определяющий количество строк клиента, которые требуется
прочитать. Читаются верхние n строк, CustomerId которых
превышает CustomerId, отправленный методу Web-сервиса.
Тестирование выполнялось путем листания большого набора строк
клиента, имеющего страницы различных размеров: 100, 500 и 1000.
GetOrders
Метод GetOrders позволяет получить из базы данных иерархию
заказов и подробных сведений о них. С помощью этого метода принимается
OrderId (Идентификатор заказа) и параметр, определяющий количество
заказов, которые требуется прочитать. Читаются верхние n строк,
OrderId которых превышает OrderId, отправленный методу Web-сервиса, и
все соответствующие подробные сведения.
Тестирование выполнялось путем пролистывания большого набора заказов
и подробных сведений о них, имеющего страницы различных размеров: 10
заказов (и 50 подробных сведений), 50 заказов (и 250 подробных сведений)
и 100 заказов (и 500 подробных сведений).
InsertCustomer
С помощью метода InsertCustomer принимаются данные клиента, в
базу данных вставляется строка клиента, и CustomerId возвращается в виде
целого числа.
InsertCustomers
С помощью метода InsertCustomers принимаются данные нескольких
клиентов, и в базу данных вставляются несколько строк клиента.
InsertOrder
С помощью метода InsertOrder данные, представляющие заказ с
несколькими подробными сведениями, принимаются и вставляются в таблицы
Order и OrderDetails базы данных. При тестировании вставлялся один
заголовок заказа, и изменялось количество подробных сведений.
Инструментарий и стратегия тестирования
Для тестирования использовался Application Center Test (ACT),
предназначенный для стресс-тестов Web-серверов и анализа проблем с
производительностью и масштабируемостью Web-приложений, в том числе
ASP-страниц и используемых ими компонентов. Более подробная информация о
создании и запуске тестов содержится в документации к ACT. Application
Center Test целесообразно использовать для тестирования методов доступа
к данным, находящимся позади Web-сервера, поскольку в нем имеется много
полезных возможностей для тестирования производительности. С его помощью
можно смоделировать большую группу пользователей путем открытия
нескольких подключений к серверу и быстрой отправки HTTP-запросов. Он
также позволяет построить реалистичные сценарии тестирования, где можно
вызвать один и тот же метод со случайным набором значений параметров.
Это важно, поскольку один и тот же метод с одинаковыми значениями
параметров не будет вызываться пользователями многократно. Другая
полезная возможность Application Center Test – это запись результатов
тестирования, в которых содержатся наиболее важные сведения о
производительности Web-приложения.
Хотя при непосредственном тестировании методов доступа к данным, в
отличие от тестирования в рамках Web-сервера, производительность и время
ответа были бы лучше, тестирование в не сохраняющей состояния
(stateless) среде является реалистичным для общих сценариев приложений;
кроме того, при обычном сравнении относительной производительности этих
методов доступа к данным издержки тестирования в не сохраняющей
состояния среде (т.е. в рамках Web-сервера) будут одинаковыми во всех
случаях.
Все рассмотренные ранее сценарии доступа к данным были реализованы
как сборка .NET Framework. Для генерации числа пользователей для сборки
с помощью Application Center Test была реализована обертка
.aspx-страницы, которой отсылались все клиентские запросы, вызывающие в
свою очередь эту сборку. Методы в сборке реализуют операцию с данными,
использующую методы ADO.NET. Они являются простыми процедурами SUB,
которые не возвращают данные .aspx-страницам. После восстановления строк
данных из базы данных, методами выполняются итерации в строках, и
локальным переменным присваиваются значения столбца. Путем создания
задержки при чтении данных из объектов ADO.NET моделируются затраты на
какую-либо операцию с данными.
Сценарии тестирования были написаны на Microsoft Visual Basic
Scripting Edition® (VBScript). Для получения другого клиента или заказа
в зависимости от метода, выполняемого из сценария тестирования, запросы
выбирались случайным образом. Например:
Dim URL
Dim UB, LB
' Установим верхний предел для списка заказов
UB = 1000000
' Установим нижний предел для списка заказов
LB = 1
' Установим URL
URL = "http://myServer/DataAccessPerf/DataReader.aspx"
' Воспользуемся функцией Randomize для инициализации функции Rnd
Randomize
Test.SendRequest(URL & "?OrderId=" & int((UB - LB + 1)*Rnd + LB))
Конфигурация системы
В следующих таблицах содержится краткий обзор конфигурации системы,
используемой для тестирования.
Таблица 1. Конфигурация клиентской системы
|
Кол-во клиентов |
Компьютер/CPU |
Кол-во CPU |
Память |
Жесткий диск |
Программное обеспечение |
|
1 |
Dell Precision WorkStation 530 MT 1694 МГц |
1 |
512 Мбайт |
16,9 Гбайт |
Microsoft Windows® XP Application Center Test |
Таблица 2. Конфигурация Web-сервера
|
Кол-во серверов |
Компьютер/CPU |
Кол-во CPU |
Память |
Жесткий диск |
Программное обеспечение |
|
1 |
Compaq Proliant 400 МГц |
4 |
640 Мбайт |
50 Гбайт |
Windows 2000 Advanced Server SP 2 .NET Framework Beta 2 |
Таблица 3. Конфигурация сервера базы данных
|
Кол-во серверов |
Компьютер/CPU |
Кол-во CPU |
Память |
Жесткий диск |
Программное обеспечение |
|
1 |
American Megatrends Atlantis
800 МГц |
2 |
1 Гбайт |
28 Гбайт |
Windows 2000 Advance Server SP 2 SQL Server Enterprise
Edition SP 2 |
Результаты тестирования производительности
Ключевые показатели производительности – это пропускная способность и
время ожидания. Для заданного объема возвращаемых данных пропускная
способность - это число клиентских запросов, обработанных за
определенную единицу времени, обычно за одну секунду. Поскольку пиковая
пропускная способность может произойти за время ответа, что недопустимо
с точки зрения применимости, отслеживалось время ожидания, измеряемое
как время ответа с помощью отчета, сгенерированного Application Center
Test для каждого тестового прогона, и тестирование данного метода
завершалось после того, как время ответа превышало 1 секунду.
GetOrderStatus
Здесь сравнивается поведение различных методов доступа к данным при
получении отдельного значения из базы данных.
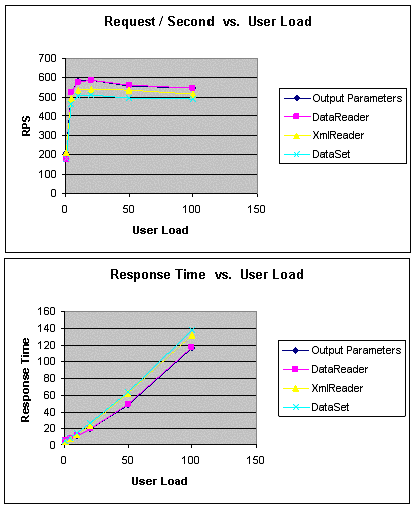 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 1. GetOrderStatus: пропускная способность и время ожидания
Примечания
- Во всех подходах используются хранимые процедуры.
- В подходе ExecuteScalar отдельное значение возвращается с
помощью метода ExecuteScalar объекта команды.
- В подходе Output Parameter отдельное значение
возвращается как выходной параметр объекта команды.
- Подход DataReader позволяет получить отдельное значение с
помощью DataReader.
- В подходе XmlReader с помощью оператора FOR XML
определяется SQL-запрос для получения отдельного значения в формате
XML в XmlReader.
Как показано на рис. 1, при получении отдельного значения
производительность подходов ExecuteScalar, Output Parameter
и DataReader очень похожа для всего диапазона изменения числа
пользователей.
Подход ExecuteScalar позволяет использовать меньше кода по
сравнению с другими подходами и поэтому может считаться лучшим вариантом
с точки зрения надежности кода.
В подходе XMLReader по сравнению с другими подходами был
достигнут самый низкий пик пропускной способности, и хранимой процедуре,
содержащей запрос FOR XML, потребовалось больше времени для выполнения,
чем запросу, используемому другими подходами.
GetCustomer
Здесь сравнивается поведение методов доступа к данным при получении
отдельной строки из базы данных.
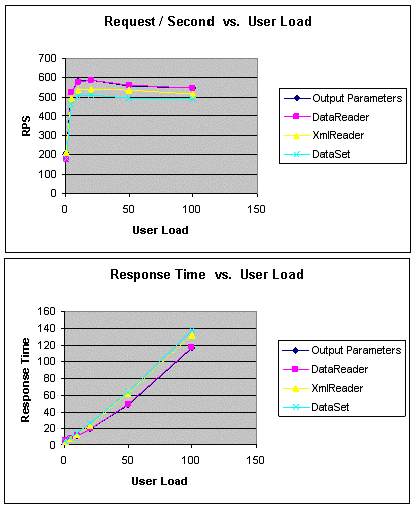 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Response Time vs. User Load = время ответа к числу
пользователей |
Рисунок 2. GetCustomer: пропускная способность и время ожидания
Примечания
- Во всех подходах используются хранимые процедуры.
- В подходе Output Parameter отдельная строка возвращается
как выходные параметры объекта команды.
- В подходе DataReader для получения отдельной строки
используетсяDataReader.
- В подходе XmlReader с помощью оператора FOR XML
определяется SQL-запрос для получения отдельной строки в формате XML
в XmlReader.
- Подход DataSet позволяет заполнить DataSet
отдельной строкой.
Как показано на рис. 2, производительность подходов Output
Parameter и DataReader очень похожа для всего диапазона
изменения числа пользователей, и их пиковая пропускная способность выше
по сравнению с двумя другими подходами. По сравнению с подходом
DataSet подход XmlReader характеризуется немного лучшей
пиковой пропускной способностью и меньшим временем ответа.
В подходе XMLReader SQL-запросу, использующему FOR XML,
потребовалось больше времени для выполнения, чем другим подобным
запросам в других подходах.
Более низкая пропускная способность в этом сценарии обусловлена
издержками на создание объекта DataSet.
GetCustomers
Здесь сравнивается производительность при выборке нескольких строк.
Для тестирования использовался набор результатов, состоящий из 100, 500
и 1000 строк и позволяющий определить влияние объема возвращенных данных
на производительность.
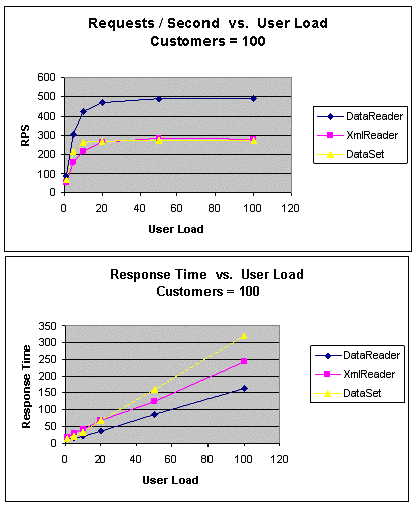 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Customers = клиенты
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 3. GetCustomers (100 клиентов): пропускная способность и
время ожидания
Примечания
- Во всех подходах используются хранимые процедуры.
- В подходе DataReader для получения нескольких строк
используется DataReader.
- В подходе XmlReader с помощью оператора FOR XML
определяется SQL-запрос для получения строк в формате XML в
XmlReader.
- Подход DataSet позволяет заполнить DataSet
несколькими строками.
Как и ожидалось, при получении нескольких строк из базы данных
уменьшается число запросов в секунду, поскольку теперь необходимо
обрабатывать и отправлять больше строк.
Как показано на рис. 3, в подходе DataReader пропускная
способность практически удваивается по сравнению с двумя другими
подходами. В подходах DataSet Набор и XmlReader
производительность почти одинакова, хотя в XmlReader она немного
выше.
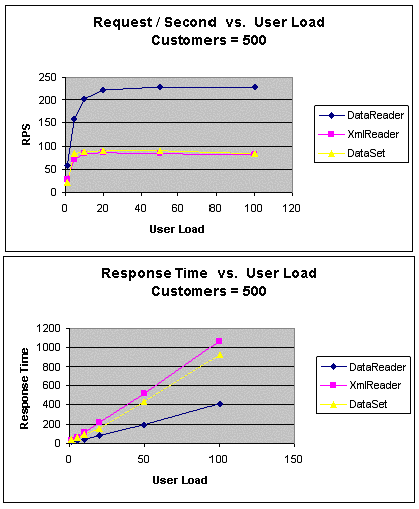 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Customers = клиенты
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 4. GetCustomers (500 клиентов): пропускная способность и
время ожидания
Для всех подходов число запросов в секунду в этом тесте продолжало
снижаться при увеличении количества возвращенных базой данных строк до
500.
При получении 500 клиентов в подходе DataReader отрыв по
пропускной способности по сравнению с другими подходами возрастает более
чем в два раза. Производительность подхода DataSet стала немного
выше по сравнению с подходом XmlReader, однако пропускная
способность осталась одинаковой.
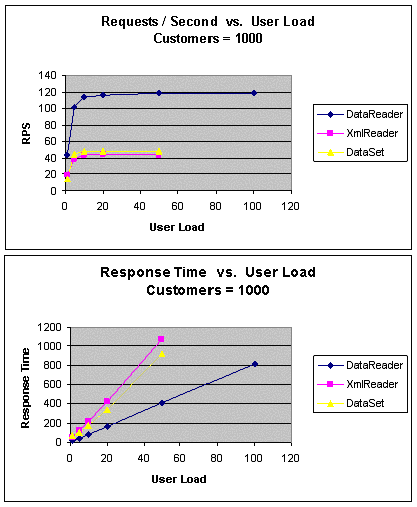 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Customers = клиенты
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 5. GetCustomers (1000 клиентов): пропускная способность и
время ожидания
При возврате 1000 строк пропускная способность подхода DataReader
выросла теперь в три раза по сравнению с другими подходами.
Тестирование подходов DataSet и XmlReader было
завершено при 50 пользователях, поскольку время их ответа превысило
порог 1 секунду, что следует из графика отношения времени ответа к числу
пользователей.
GetOrders
Здесь сравнивается производительность при выборке иерархического
набора результатов. Для тестирования использовался набор результатов,
состоящий из 10 заказов (и 50 подробных сведений), 50 заказов (и 250
подробных сведений), 100 заказов (и 500 подробных сведений) и 200
заказов (и 1000 подробных сведений).
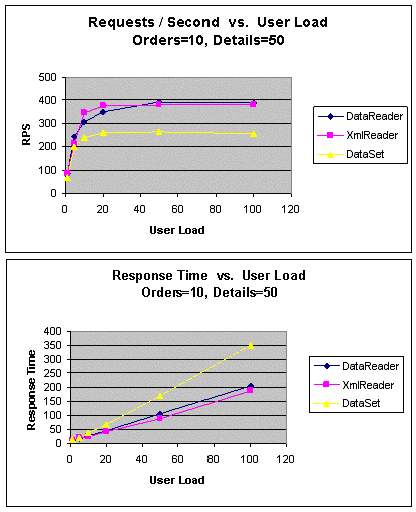 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Orders = заказы
Details = подробные сведения о заказе
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 6. GetOrders (10 заказов, 50 подробных сведений): пропускная
способность и время ожидания
Примечания
- Во всех подходах используются хранимые процедуры.
- В подходе DataReader DataReader заполняется
хранимой процедурой, возвращающей два набора результатов: с заказами
и с подробными сведениями. Так как DataReader доступен только
для чтения, подробные сведения о заказах не были связаны со своими
заказами, поскольку они читались из DataReader.
- В подходе XmlReader с помощью оператора FOR XML EXPLICIT
определяется SQL-запрос для получения заказов и подробных сведений о
них в формате иерархического XML. Заказы и подробные сведения были
связаны, поскольку они читались из XmlReader;
- Для заполнения DataSet в подходах DataSet и
DataReader используется одинаковая хранимая процедура. Между
заказами и подробными сведениями в DataTables были
установлены родительские/дочерние отношения; заказы и подробные
сведения были связаны, поскольку они читались из DataSet.
Тестирование началось с набора результатов, состоящего из 10 заказов
и 50 подробных сведений. Как показано на рис. 6, в подходе DataReader
была достигнута пиковая пропускная способность при 50 параллельных
пользователях, которая немного превышала пропускную способность
XmlReader, ставшую неизменной при 20 параллельных пользователях.
Подход DataSet характеризуется более низкой пиковой пропускной
способностью и большим временем ожидания. В данном случае необходимы
издержки на создание двух DataTables для хранения строк заказов и
подробных сведений и других связанных с DataTables подобъектов.
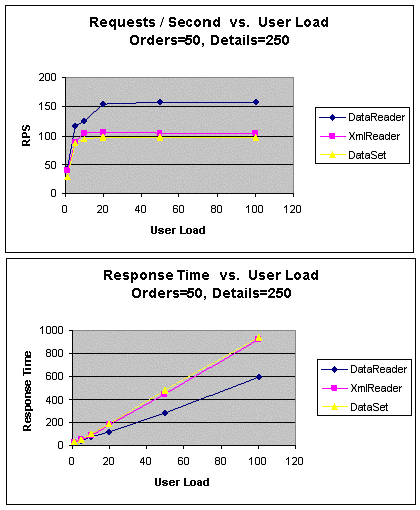 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Orders = заказы
Details = подробные сведения о заказе
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 7. GetOrders (50 заказов, 250 подробных сведений): пропускная
способность и время ожидания
Как показано на диаграмме на рис. 7, пропускная способность у
подхода DataReader лучше, хотя, как уже было отмечено, заказы и
подробные сведения не связаны между собой.
Несмотря на схожую пропускную способность подходов XmlReader и
DataSet, запрос FOR XML EXPLICIT, применяемый в подходе
XmlReader, приводит к значительно большей загрузке CPU сервера базы
данных, чем тот же запрос в подходе DataSet, приводящий к большей
загрузке CPU Web-сервера.
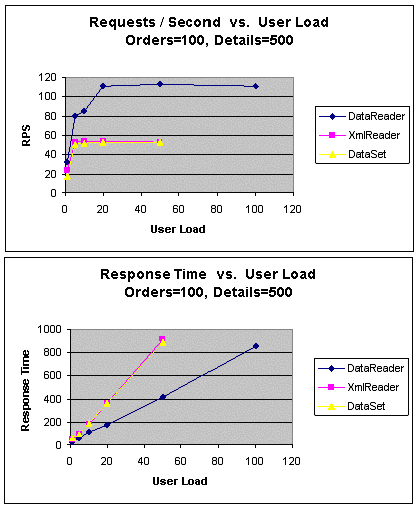 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Orders = заказы
Details = подробные сведения о заказе
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 8. GetOrders (100 заказов, 500 подробных сведений):
пропускная способность и время ожидания
Как показано на рис. 8, в подходе DataReader отрыв по
пропускной способности по сравнению с двумя другими подходами возрастает
в два раза. Однако не следует забывать, что в подходе DataReader
остаются связанными больше заказов и подробных сведений, чем в любом
другом месте в приложении.
Сравнение DataReader и DataSet
Во всех предыдущих тестах DataReader превосходил по
производительности DataSet. Как отмечалось ранее,
производительность DataReader лучше по причине отсутствия
издержек на производительность и память, связанных с созданием
DataSet.
DataReader – это лучший выбор для приложений, которым
требуется оптимизированный однонаправленный доступ к данным только для
чтения. Чем быстрее загрузить данные из DataReader и закрыть
DataReader и подключение к базе данных, тем лучшей
производительности можно достичь. Поскольку при использовании
DataReader подключение к базе данных сохраняется и не может
использоваться для других целей при чтении данных приложением,
масштабируемость может быть ограничена, если DataReader
удерживается приложением достаточно долго и вызывает конфликтную
ситуацию. Для DataSet подключение требуется только при его
заполнении. После завершения заполнения подключение можно закрыть и
возвратить в пул. Задержка чтения данных из DataSet не приведет к
конфликтной ситуации, поскольку подключение скорее всего уже будет
возвращено в пул.
Во всех предыдущих тестах максимальный размер пула подключений был
равен 100 (размер по умолчанию), и поскольку число одновременно
подключенных пользователей никогда не превышало 100, конфликтная
ситуация с подключениями не возникала. При тестировании требовалось
определить поведение DataReader и DataSet при небольшой
задержке при загрузке данных, приводящей в свою очередь к конфликтной
ситуации с подключениями.
В следующем тесте при чтении данных из этих объектов использовалась
задержка на 20 миллисекунд (мс) и максимальный размер пула 10. Это
привело к конфликтной ситуации.
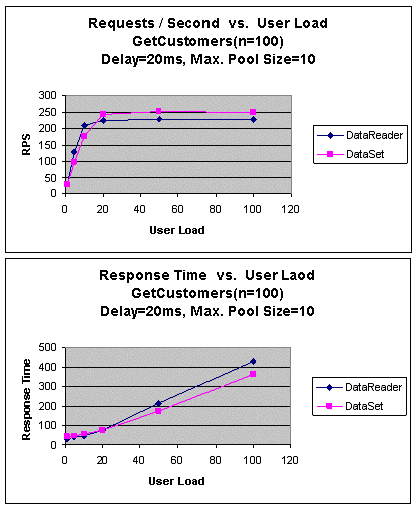 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Delay = задержка
Max. Pool Size = макс. размер пула
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 9. GetCustomers (с конфликтной ситуацией): пропускная
способность и время ожидания
Примечания
- DataReader используется в подходе DataReader для
получения иерархических данных, содержащих заказы и подробные
сведения о них.
- Подход DataSet позволяет заполнить DataSet
заказами и подробными сведениями о них.
Когда число параллельных пользователей достигло 20, возникла
конфликтная ситуация с подключением к базе данных, и, как показано на
рис. 9, производительность DataReader начала снижаться. Обратите
внимание, что DataSet превзошел по производительности
DataReader, когда число параллельных пользователей превысило 20.
Также следует отметить, что время ответа DataReader было больше,
чем у DataSet, когда число параллельных пользователей превысило
20.
В следующем тесте при чтении данных из этих объектов использовалась
задержка на 50 мс и максимальный размер пула 12.
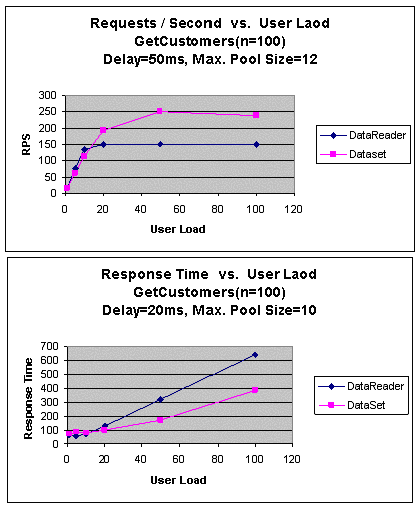 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Delay = задержка
Max. Pool Size = макс. размер пула
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 10. GetCustomers (с конфликтной ситуацией): пропускная
способность и время ожидания
Примечания
DataReader используется в подходе DataReader для
получения иерархических данных, содержащих заказы и подробные сведения о
них.
Подход DataSet позволяет заполнить DataSet заказами и
подробными сведениями о них.
Как показано на рис. 10, производительность DataReader начала
снижаться, когда число параллельных пользователей превысило 20, и
фактически возникла конфликтная ситуация с подключением к базе данных.
Обратите внимание, что время ответа DataReader было больше,
чем у DataSet, когда число параллельных пользователей превысило
20.
InsertCustomer
Установив, как сравниваются методы доступа к данным при чтении
данных, перейдем к их сравнению при записи данных. В этом тесте в базу
данных был вставлен один клиент.
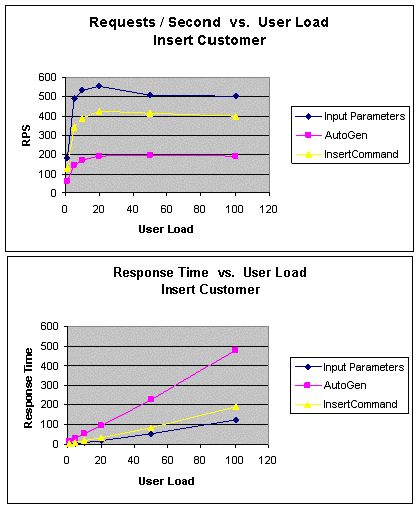 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Insert Customer = вставка клиента
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 11. InsertCustomer: пропускная способность и время ожидания
Примечания
- В подходах Input Parameters и InsertCommand
используются хранимые процедуры;
- В подходе Input Parameters входные параметры объекта
команды заполняются информацией о новом клиенте, и для выполнения
хранимой процедуры используется метод ExecuteNonQuery;
- В подходе AutoGen команда Insert, относящаяся к
DataAdapter, генерируется автоматически на основе команды
Select при вызове метода Update;
- В подходе InsertCommand определяется свойство
InsertCommand для DataAdapter.
В подходе Autogen при вызове в DataAdapter метода
Update объект CommandBuilder, связанный с DataAdapter,
автоматически генерирует команду Insert, зависящую от команды
Select, которая была определена для DataAdapter. Этим
объясняется более низкая производительность этого подхода по сравнению с
двумя другими подходами. Преимущество этого подхода состоит в упрощении
кода и сокращении его объема, поскольку определять свои собственные
команды вставки, обновления и удаления не требуется. Сравним
производительность этого подхода с подходом InsertCommand, где в
DataAdapter было явно определено свойство InsertCommand.
В подходе Input Parameters входные параметры объекта команды
заполняются информацией о новом клиенте, и для выполнения хранимой
процедуры SQL вызывается метод ExecuteNonQuery. Как показано на
рис. 11, этот подход превосходит по производительности два других
подхода. В подходе InsertCommand возникают издержки на
производительность и память при создании DataSet, в подходе
Output Parameters достигается более высокая производительность по
причине отсутствия этих издержек.
InsertCustomers
Был проведен ряд тестов для определения влияния вставки нескольких
строк клиентов на производительность объектов ADO.NET. Количество строк
клиента изменялось для увеличения объема вставляемых данных.
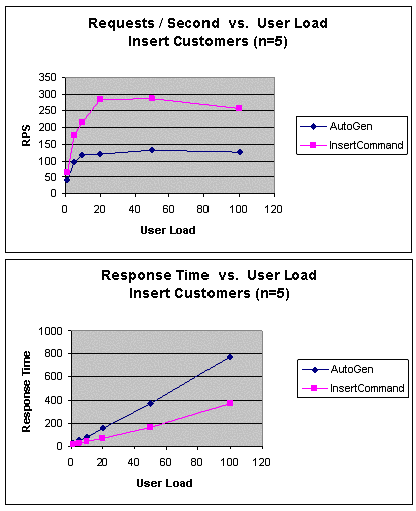 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Insert Customers = вставка клиентов
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 12. InsertCustomers (n=5): пропускная способность и время
ожидания
Примечания
- В подходе InsertCommand используются хранимые процедуры.
- В подходе AutoGen команда Insert, относящаяся к
DataAdapter, генерируется автоматически на основе команды
Select при вызове метода Update.
- В подходе InsertCommand определяется свойство
InsertCommand для DataAdapter.
Как и ожидалось, по сравнению с подходом Autogen
производительность в подходе InsertCommand, в котором было
определено свойство InsertCommand для DataAdapter, намного
лучше. Этот подход характеризуется меньшим временем ответа и лучшей
пропускной способностью для всего диапазона изменения числа
пользователей.
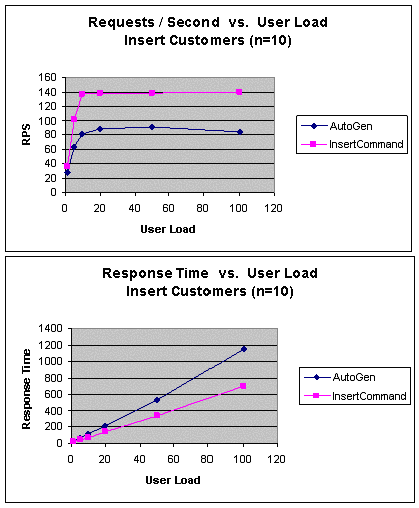 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Insert Customers = вставка клиентов
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 13. InsertCustomers (n=10): пропускная способность и время
ожидания
Как показано на рис. 13, подход InsertCommand по-прежнему
превосходит по пропускной способности подход AutoGen при вставке
большего объема данных, однако различия между подходами уменьшаются,
поскольку затраты на автоматически сгенерированную команду снижаются при
увеличении объема данных.
InsertOrder
В последнем ряде тестов сравнивается производительность при вставке
иерархии заказа и подробных сведений о нем. Количество строк подробных
сведений о заказе изменялось для увеличения объема вставляемых данных.
Поскольку в таблице Orders (Заказы) содержится столбец автоприращения
(OrderId) как первичный ключ таблицы, вставить иерархические строки в
таблицы Orders (родительская) и OrderDetails (Подробные сведения о
заказе - дочерняя) с помощью автоматически сгенерированной команды
Insert для DataAdapter, связанного с таблицей Orders, было
невозможно. Прежде всего, это происходит вследствие проблемы с
автоматически сгенерированными вставками, когда первичный ключ Id для
столбца Identity не возвращается в DataSet. Поэтому подход
Autogen является фактически гибридом, в котором InsertCommand
является для таблицы Orders хранимой процедурой (возвращающей OrderId),
а команда Insert для DataAdapter, связанного с таблицей
Orders, генерируется автоматически.
В подходе OpenXml для свойства InsertCommand в
DataAdapter, связанного с таблицей Orders, выбрана хранимая
процедура, принимающая заказ и подробные сведения о нем в представлении
XML. После вставки строк в таблицы Orders и OrderDetails в DataSet,
хранящиеся в DataSet данные в представлении XML извлекаются и
передаются хранимой процедуре, выполняющей с помощью системной хранимой
процедуры sp_xml_preparedocument и метода OPENXML
соответствующие вставки в таблицы Orders и OrderDetails базы данных.
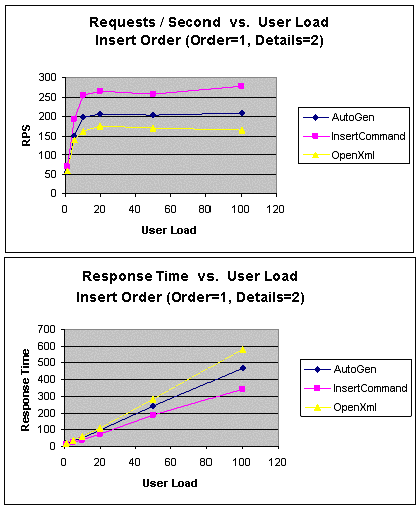 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Insert Order = вставка заказа
Order = заказ
Details = подробные сведения о заказе
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 14. InsertOrder (1 заказ, 2 подробные сведения о заказе):
пропускная способность и время ожидания
- В подходахInsertCommand и OpenXml используются
хранимые процедуры.
- Подход Autogen является гибридом, использующим хранимую
процедуру для вставки заказа и автоматически сгенерированную команду
Insert для таблицы OrderDetails на основе ее команды
Select.
- В подходе InsertCommand определены свойства
InsertCommand для обеих DataAdapter.
- В подходе OpenXml данные Order и OrderDetails в
представлении XML передаются в виде NVarChar хранимой
процедуре, выполняющей их анализ и соответствующие вставки.
Как показано на рис. 14, производительность подхода InsertCommand
выше, чем у гибридного подхода AutoGen, превосходящего в свою
очередь по производительности подход OpenXml.
Более низкая производительность этого подхода по сравнению с подходом
InsertCommand объясняется издержками на автоматическую генерацию
команды Insert во время выполнения и большей эффективностью
хранимых процедур по сравнению с динамическим SQL.
Меньшее число циклов обработки в базе данных в подходе OpenXml
по сравнению с другими подходами не является самым важным фактором,
влияющем на производительность в этом тесте при выполнении только трех
вставок.
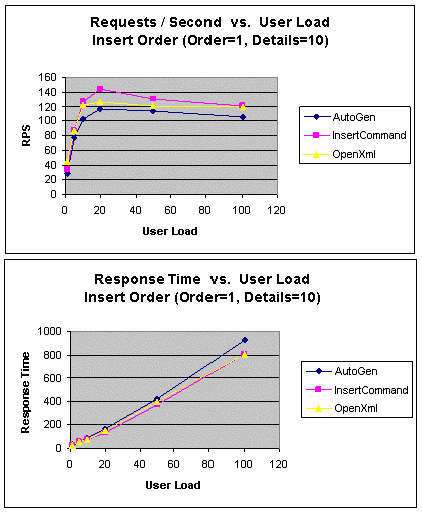 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Insert Order = вставка заказа
Order = заказ
Details = подробные сведения о заказе
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 15. InsertOrder (1 заказ, 10 подробных сведений о заказе):
пропускная способность и время ожидания
В следующем тесте исследовалась вставка 1 заказа и 10 подробных
сведений о нем. Как показано на рис. 15, относительная
производительность в подходе OpenXml значительно выше, чем в
других подходах, поскольку издержка на циклы обработки становится
существенным фактором. В этом тесте единственным циклом обработки,
используемым в подходе OpenXml, заменяются 11 циклов обработки,
необходимых для других подходов.
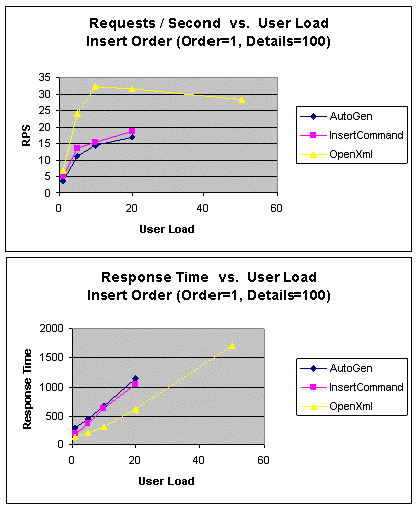 |
Дополнительная информация по рисунку
Request / Second vs. User Load = число запросов в секунду к
числу пользователей
Insert Order = вставка заказа
Order = заказ
Details = подробные сведения о заказе
Response Time vs. User Load = время ответа к числу
пользователей |
Рис. 16. InsertOrder (1 заказ, 100 подробных сведений о заказе):
пропускная способность и время ожидания
Примечание
- В подходе OpenXml данные Order и OrderDetails в
представлении XML передаются в виде NText хранимой процедуре,
выполняющей их анализ и соответствующие вставки.
В последнем тесте был вставлен 1 заказ и 100 подробных сведений о
нем. В этом тесте единственным циклом обработки, используемым в подходе
OpenXml, заменяется 101 цикл обработки, необходимый для других
подходов. Как показано на рис. 16, теперь пропускная способность в
подходе OpenXml намного выше, чем в других подходах. Следует
также отметить, что в этом тесте пропускная способность AutoGen и
InsertCommand примерно одинакова вследствие снижения издержек на
автоматическую генерацию.
Заключение
Производительность и масштабируемость – одни из многих факторов,
которые следует рассматривать при выборе метода доступа к данным.
Согласно этим сравнениям пропускная способность может быть часто
умножена путем предпочтения одного метода доступа к данным другому, тем
не менее, для всех сценариев лучшего универсального подхода не
существует. Поскольку общая производительность зависит от многих
факторов, тестирование производительности с помощью реалистичных
сценариев заменить невозможно.

 Форум Программиста
Форум Программиста Новости
Новости Обзоры
Обзоры Магазин Программиста
Магазин Программиста Каталог ссылок
Каталог ссылок Поиск
Поиск Добавить файл
Добавить файл Обратная связь
Обратная связь 