В прошлом месяце Брэтт представил Document Object Model, элементы
которой работают за кулисами ваших Web-страниц. В этом месяце он рассматривает
DOM еще детальнее. Узнайте, как создавать, удалять и изменять части DOM-дерева,
и сделайте очередной шаг к динамическому обновлению ваших
Web-страниц!
Если вы следили за дискуссией в этой серии статей в прошлом
месяце, значит, имеете начальное представление о том, что происходит при
отображении Web-браузером ваших Web-страниц. Я объяснял, что когда определенные
вами для страницы HTML и CSS передаются в Web-браузер, они транслируются из
текстовой в объектную модель. Это истинно и для простого кода и для сложного,
для кода, расположенного в одном файле и в отдельных файлах. Браузер напрямую
работает с объектной моделью, а не с предоставленными вами текстовыми файлами.
Используемая браузером модель называется Document Object Model. Она
соединяет объекты, представляющие элементы, атрибуты и текст в ваших документах.
В эту объектную модель внедрены все стили, значения и даже большинство из
пробелов вашего HTML и CSS-кода. Конкретная модель для данной Web-страницы
называется DOM-деревом страницы.
Понимание того, что представляет собой DOM-дерево, и даже знание того, как
оно представляет ваш код HTML и CSS - это только первый шаг на пути к управлению
вашими Web-страницами. Вы должны научиться работать с DOM-деревом конкретной
Web-страницы. Например, если вы добавите элемент к DOM-дереву, этот элемент
немедленно появится в браузере пользователя без перезагрузки страницы. Удалите
какой-нибудь текст из DOM-дерева, и этот текст исчезнет с экрана пользователя.
Вы можете изменить интерфейс и взаимодействовать с интерфейсом пользователя
через DOM, что дает вам огромную мощь и гибкость при программировании. Изучив
работу с DOM-деревом, вы сделаете гигантский шаг навстречу овладению развитыми,
интерактивными, динамичными Web-сайтами.
Обращаю внимание на то, что следующий материал основан на статье "Исследование
DOM для Web-ответа"; если вы ее не читали, то, возможно, захотите сделать
это перед продолжением работы над данной статьей.
 |
Вопросы произношения акронимов
Вообще говоря, Document Object Model могла бы легко называться Document Node
Model. Но в своем большинстве люди, конечно же, не знают, что означает термин
node (узел), да и произносить "DNM" не так удобно, как "DOM", поэтому
легко объяснить, почему W3C выбрала именно
DOM. | |
Разные браузеры, разные
языки
Document Object Model - это стандарт W3C (ссылки на W3C приведены в разделе
"Ресурсы"). По этой причине все современные
Web-браузеры поддерживают DOM, по крайней мере, в некоторой степени. Хотя и
существуют некоторые различия между браузерами, если вы использовали базовую
DOM-функциональность (и обращали внимание на несколько специальных ситуаций и
исключений), ваш DOM-код будет работать в любом браузере одинаково. Написанный
вами код для изменения Web-страницы в Opera будет работать с Safari®, Firefox®,
Microsoft® Internet Explorer® и Mozilla®.
DOM также является не зависящей от языка спецификацией; другими
словами, вы можете использовать ее во многих популярных языках программирования.
W3C определяет для DOM несколько правил связывания с разными языками.
Правила связывания языка - это просто API, определенный для разрешения
использования DOM в конкретном языке. Например, вы можете найти однозначно
определенные правила связывания DOM для C, Java и JavaScript. Следовательно, вы
можете использовать DOM в любом из этих языков. Правила связывания доступны
также и для нескольких других языков, хотя многие из них не определены не W3C, а
третьими сторонами.
В данной серии статей я сконцентрируюсь на правилах связывания DOM для
JavaScript. Это имеет смысл, поскольку большинство разработок асинхронных
приложений основано на написании JavaScript-кода для работы в Web-браузерах. С
JavaScript и DOM вы можете изменять пользовательский интерфейс динамически,
реагируя на пользовательские события и ввод, и, более того, используя для всего
этого четко стандартизированный JavaScript.
Несмотря на сказанное выше, я призываю вас попробовать поработать с DOM и в
других языках. Например, вы можете использовать правила связывания для Java при
работе не только с HTML, но также и с XML (я буду рассматривать это в одной из
следующих статей). То есть, знания, которые вы получите здесь, выходят далеко за
рамки HTML и применимы не только в JavaScript-программировании клиентского
кода.
Абстрактный узел
Node является самым главным типом объекта в DOM. Фактически, как вы узнаете
из этой статьи, почти каждый второй объект, определенный в DOM, расширяет объект
node. Но, прежде чем вы углубитесь в семантику, вы должны понять концепцию,
представляемую узлом; изучить актуальные свойства и методы node очень
просто.
В DOM-дереве почти все, что вы встречаете, является узлом. Каждый элемент
является на своем наиболее базовом уровне узлом в DOM-дереве. Каждый атрибут -
это узел. Каждый кусочек текста - это узел. Даже команды, специальные символы
(например, © - символ авторского права) и объявления DOCTYPE (если у
вас они есть в HTML или XHTML) являются узлами. Поэтому, перед обсуждением
особенностей конкретных типов вы должны понять, что такое узел.
Узел - это…
Простейшее определение: узел - это просто одна отдельная вещь в DOM-дереве.
Неясность термина "вещь" преднамеренна, поскольку она конкретна настолько,
насколько мы ее представляем. Например, возможно не очевидно, что элемент в
вашем HTML, допустим img, и часть текста в HTML, допустим
"Прокрутите страницу вниз для получения подробной информации", имеют много
общего. Но это из-за того, что вы, вероятно, думаете о функции этих
конкретных типов и концентрируетесь на их различиях.
Но представьте, что каждый элемент и часть текста в DOM-дереве имеет
предка; этот предок является либо потомком другого элемента (например,
когда img вложен в элемент p), либо самым верхним
элементом DOM-дерева (который является специальным случаем для каждого
документа, и с которым вы используете элемент html). Также
представьте, что оба элемента и текст имеют тип. Типом элемента,
очевидно, является element; типом текста - text. Каждый узел имеет также четко
определенную структуру: имеет ли он узел (или узлы) ниже себя, такие как
элементы-потомки? Имеет ли он одноуровневые узлы (узлы "next to" элемента
или текста)? Какому документу принадлежит каждый узел?
Очевидно, что многое из этого звучит довольно абстрактно. Фактически, может
даже показаться глупой фраза, что типом элемента является … ммм… элемент. Однако
вы должны абстрагироваться для представления значения узла как общего объектного
типа.
Общий объектный тип
Одним из действий, которое вы будете выполнять чаще, чем любое другое в вашем
DOM-коде, является навигация по DOM-дереву страницы. Например, вы можете найти
форму по ее атрибуту "id" и начать работать с элементами и текстом, вложенными в
эту форму. К ним могут относиться текстовые инструкции, метки для полей вода,
элементы ввода и, возможно, другие HTML-элемента, такие как img и
ссылки (элементы a). Если элементы и текст имеют полностью
различные типы, тогда вы должны написать совершенно разные фрагменты кода для
перемещения от одного типа к другому.
Ситуация меняется, если вы используете общий тип узла. В этом случае вы
можете просто перемещаться от узла к узлу и беспокоиться о типе только
тогда, когда вы захотите сделать что-нибудь конкретное с элементом или текстом.
Когда вы просто перемещаетесь по DOM-дереву, то будете использовать те же
операции для перемещения к предку элемента или его потомку, что и с любым другим
типом узла. Вы должны работать по-особому с таким типом узла как элемент или
текст только тогда, когда требуется что-то конкретное от определенного типа
узла, например атрибуты элемента. Представление о каждом объекте в DOM-дереве
просто как об узле намного упрощает работу. Думая так, я далее рассмотрю, что
именно должна предложить конструкция DOM Node (начиная с ее свойств и
методов).
Свойства узла
При работе с узлами DOM-дерева вам могут понадобиться несколько свойств и
методов. Давайте рассмотри их первыми. Основными свойствами DOM-узла
являются:
nodeName хранит имя узла (подробнее ниже).
nodeValue хранит "значение" узла (подробнее ниже).
parentNode возвращает предка узла. Помните: каждый элемент,
атрибут и текст имеет родительский узел.
childNodes список потомков узла. При работе с HTML этот список
полезен только тогда, когда вы имеете дело с элементом; текстовые узлы и
узлы-атрибуты не имеют потомков.
firstChild это просто сокращение для первого узла в списке
childNodes.
lastChild это еще одно сокращение - для последнего узла в
списке childNodes.
previousSibling возвращает узел, находящийся перед
текущим узлом. Другими словами, он возвращает узел, предшествующий текущему в
списке childNodes его предка (если не понятно - перечитайте это
последнее предложение).
nextSibling свойство, аналогичное previousSibling;
возвращает следующий узел в спиcке childNodes предка.
attributes полезно только для узлов-элементов; возвращает
список атрибутов элемента.
Несколько других свойств применяются с более общими XML-документами и почти
не применяются при работе с Web-страницами, основанными на HTML.
Необычные свойства
Большинство из определенных выше свойств не требует дополнительного
пояснения, за исключением свойств nodeName и
nodeValue. Вместо простого объяснения этих свойств рассмотрим пару
странных вопросов. Каким должно быть свойство nodeName для
текстового узла? И, аналогично, каким должно быть свойство
nodeValue для элемента?
Если эти вопросы поставили вас в тупик, значит вы уже понимаете потенциальную
запутанность, присущую этим свойствам. nodeName и
nodeValue действительно не применимы для всех типов узлов
(это также истинно для некоторых других свойств узла). Это демонстрирует
ключевую концепцию: любое их этих свойств может возвратить нулевое значение
(иногда показываемое в JavaScript как "undefined"). То есть, например, свойство
nodeName для текстового узла равно null (или "undefined" в
некоторых браузерах), поскольку текстовые узлы не имеют имени.
nodeValue, как и ожидалось, возвращает текст узла.
Аналогично, элементы имеют nodeName (имя элемента), но значение
свойства nodeValue всегда равно null. Атрибуты имеют значения обоих
свойств nodeName и nodeValue. Я поговорю об этих
индивидуальных типах подробнее в следующем разделе, но поскольку эти свойства
являются частью каждого узла, их стоит упомянуть здесь.
Теперь посмотрим на листинг 1, в котором показано
несколько свойств узла в действии.
Листинг 1.
Использование свойств узла в DOM
// Эти две первые строки получают DOM-дерево текущей Web-страницы,
// и затем элемент <html> для этого дерева
var myDocument = document;
var htmlElement = myDocument.documentElement;
// Какое имя элемента <html>? "html"
alert("The root element of the page is " + htmlElement.nodeName);
// Ищем элемент <head>
var headElement = htmlElement.getElementsByTagName("head")[0];
if (headElement != null) {
alert("We found the head element, named " + headElement.nodeName);
// Отображаем элемент title страницы
var titleElement = headElement.getElementsByTagName("title")[0];
if (titleElement != null) {
// text будет первым дочерним узлом элемента <title>
var titleText = titleElement.firstChild;
// Мы можем получить текст текстового узла, используя nodeValue
alert("The page title is '" + titleText.nodeValue + "'");
}
// После <head> идет <body>
var bodyElement = headElement.nextSibling;
while (bodyElement.nodeName.toLowerCase() != "body") {
bodyElement = bodyElement.nextSibling;
}
// Мы нашли элемент <body>...
// Мы сделаем больше, когда узнаем некоторые методы узлов.
}
|
 |
Методы узла
Рассмотрим методы, доступные всем узлам (как и в ситуации со свойствами я
пропустил несколько методов, которые не применяются в большинстве операций HTML
DOM):
insertBefore(newChild, referenceNode) вставляет узел
newChild перед referenceNode. Помните о том, что вы
должны вызывать его в предназначенном предке newChild.
replaceChild(newChild, oldChild) замещает узел
oldChild узлом newChild.
removeChild(oldChild) удаляет узел oldChild из
узла, в котором выполняется функция.
appendChild(newChild) добавляет узел newChild к
узлу, в котором выполняется функция. newChild добавляется в конце
потомков целевого узла.
hasChildNodes() возвращает true, если вызываемый узел имеет
потомков, и false, если не имеет.
hasAttributes() возвращает true, если вызываемый узел имеет
атрибуты, и false, если не имеет.
Вы заметите, что, по большей части, все эти методы имеют дело с потомками
узла. Это их первичное назначение. Если вы просто пытаетесь собрать значение
текстового узла или имя элемента, то, возможно, не часто будете вызывать методы,
поскольку можно просто использовать свойства узла. Код, приведенный в листинге 2, создан на основе кода из листинга
1 и использует несколько из перечисленных выше методов.
Листинг 2. Использование методов узла в DOM
// Эти две первые строки получают DOM-дерево текущей Web-страницы,
// и затем элемент <html> для этого дерева
var myDocument = document;
var htmlElement = myDocument.documentElement;
// Какое имя элемента <html>? "html"
alert("The root element of the page is " + htmlElement.nodeName);
// Ищем элемент <head>
var headElement = htmlElement.getElementsByTagName("head")[0];
if (headElement != null) {
alert("We found the head element, named " + headElement.nodeName);
// Отображаем элемент title страницы
var titleElement = headElement.getElementsByTagName("title")[0];
if (titleElement != null) {
// text будет первым дочерним узлом элемента <title>
var titleText = titleElement.firstChild;
// Мы можем получить текст текстового узла, используя nodeValue
alert("The page title is '" + titleText.nodeValue + "'");
}
// После <head> идет <body>
var bodyElement = headElement.nextSibling;
while (bodyElement.nodeName.toLowerCase() != "body") {
bodyElement = bodyElement.nextSibling;
}
// Мы нашли элемент <body>...
// Удалить все элементы <img> верхнего уровня из тела
if (bodyElement.hasChildNodes()) {
for (i=0; i<bodyElement.childNodes.length; i++) {
var currentNode = bodyElement.childNodes[i];
if (currentNode.nodeName.toLowerCase() == "img") {
bodyElement.removeChild(currentNode);
}
}
}
}
|
Выполните тестирование!
До сих пор вы видели только два примера (листинг 1 и 2), но они должны дать вам понятие о том, что можно сделать
при запуске управления DOM-деревом. Если вы хотите попробовать поработать с
кодом, просто сохраните листинг 3 в HTML-файле и загрузите
его в ваш Web-браузер.
Листинг 3. HTML-файл с некоторым
JavaScript-кодом, использующим DOM
<html>
<head>
<title>JavaScript and the DOM</title>
<script language="JavaScript">
function test() {
// Эти две первые строки получают DOM-дерево текущей Web-страницы,
// и затем элемент <html> для этого дерева
var myDocument = document;
var htmlElement = myDocument.documentElement;
// Какое имя элемента <html>? "html"
alert("The root element of the page is " + htmlElement.nodeName);
// Ищем элемент <head>
var headElement = htmlElement.getElementsByTagName("head")[0];
if (headElement != null) {
alert("We found the head element, named " + headElement.nodeName);
// Отображаем элемент title страницы
var titleElement = headElement.getElementsByTagName("title")[0];
if (titleElement != null) {
// text будет первым дочерним узлом элемента <title>
var titleText = titleElement.firstChild;
// Мы можем получить текст текстового узла, используя nodeValue
alert("The page title is '" + titleText.nodeValue + "'");
}
// После <head> идет <body>
var bodyElement = headElement.nextSibling;
while (bodyElement.nodeName.toLowerCase() != "body") {
bodyElement = bodyElement.nextSibling;
}
// Мы нашли элемент <body>...
// Удалить все элементы <img> верхнего уровня из тела
if (bodyElement.hasChildNodes()) {
for (i=0; i<bodyElement.childNodes.length; i++) {
var currentNode = bodyElement.childNodes[i];
if (currentNode.nodeName.toLowerCase() == "img") {
bodyElement.removeChild(currentNode);
}
}
}
}
}
</script>
</head>
<body>
<p>JavaScript and DOM are a perfect match.
You can read more in <i>Head Rush Ajax</i>.</p>
<img src="http://www.headfirstlabs.com/Images/hraj_cover-150.jpg" />
<input type="button" value="Test me!" onClick="test();" />
</body>
</html>
|
После загрузки этой страницы в ваш браузер вы должны увидеть что-то похоже на
рисунок 1.
Рисунок 1. Пример
HTML-страницы с кнопкой для запуска JavaScript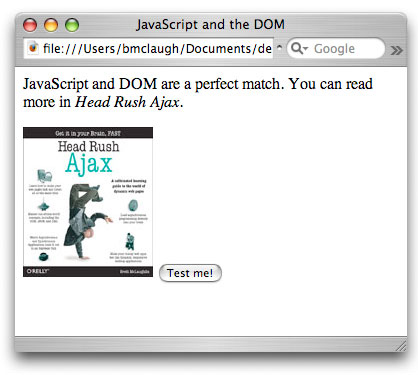
Нажмите кнопку Test me! и вы увидите окна предупреждений, показанные
на рисунке 2.
Рисунок 2. Окна
предупреждений, показывающие имя элемента при помощи nodeValue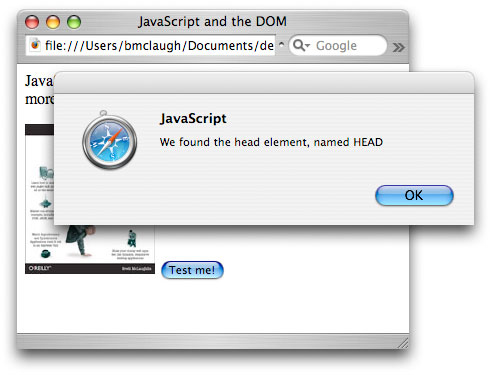
Когда код завершает работу, изображения удаляются со страницы в режиме
реального времени, как показано на рисунке 3.
Рисунок 3. Изображения удаляются со страницы в режиме реального
времени при помощи JavaScript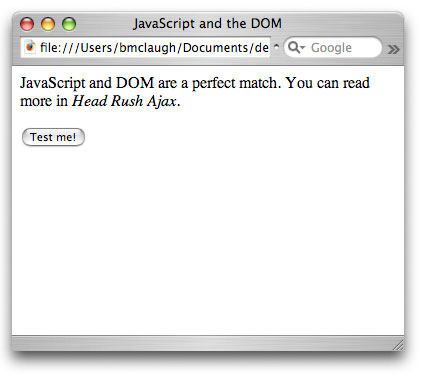
Замечания по дизайну API
Посмотрите опять на свойства и методы, доступные каждому узлу. Они
иллюстрируют ключевой момент DOM для тех, кто комфортно чувствует себя в
объектно-ориентированном (OO) программировании: DOM не является таким уж
объектно-ориентированным API. Во-первых, во многих ситуациях вы будете
использовать свойства объекта напрямую, без вызова метода объекта node. Нет
метода getNodeName(), например; вы просто сразу используете
свойство nodeName. То есть, объекты node (а также и другие
DOM-объекты) выставляют многие из своих данных через свойства, а не функции.
Во-вторых, именование объектов и методов в DOM может показаться немного
странным, если вы работали с перегруженными объектами и
объектно-ориентированными API, в частности, в таких языках как Java или C++. DOM
должен работать в C, Java и JavaScript (перечислим только их), поэтому при
проектировании API были сделаны некоторые уступки. Например, вы увидите два
различных метода объекта NamedNodeMap, которые выглядят примерно
так:
getNamedItem(String name)
getNamedItemNS(Node node)
Для OO-программистов это выглядит довольно странным. Два метода с одинаковым
предназначением, но один в качестве параметра принимает String, а другой
Node. В большинстве OO API вы использовали бы одно и то же название
метода для обеих версий. Виртуальная машина, выполняющая ваш код, распознавала
бы, какой метод использовать на основе типа объекта, переданного вами в
метод.
Проблема состоит в том, что JavaScript не поддерживает эту технологию,
называемую перегрузкой методов. Другими словами, JavaScript требует
наличия одного метода или функции с данным именем. Поэтому, если у вас есть
метод getNamedItem(), принимающий строку, вы не можете иметь любой
другой метод или функцию с именем getNamedItem(), даже если вторая
версия принимает различные типы аргументов (или даже принимает совершенно другой
набор аргументов). JavaScript выдаст ошибку, и ваш код не будет работать так,
как по вашему мнению должен работать.
По существу, DOM сознательно избегает перегрузки методов и других технологий
OO-программирования. Это гарантирует, что API будет работать в нескольких
языках, включая те, которые не поддерживают технологии OO-программирования. В
результате вы должны просто изучить несколько дополнительных названий методов.
Положительная сторона - вы можете изучать DOM в любом языке программирования,
например Java, и знать, что эти же названия методов и конструкций кода будут
работать в любых других языках, имеющих реализацию DOM, например,
JavaScript.
Пусть побеспокоится
программист
Что же касается дизайна API в общем (допустим, вы внимательно его изучили),
то вы можете удивиться: "Зачем нужны свойства типа node, которые не являются
общими для всех?" Это хороший вопрос, а ответ лежит больше в области политики и
принятия решений, чем каких-либо технических причин. Короче говоря, ответ такой,
"Кто его знает! Но это немного раздражает, не так ли?"
Свойство nodeName предназначено для того, чтобы каждый тип имел
имя; но во многих ситуациях это имя либо не определено, либо является странным,
внутренним именем, не имеющим значения для программистов (например, в Java,
nodeName текстового узла имеет значение "#text" во многих
ситуациях). По существу, вы должны предположить, что обработка ошибок оставлена
для вас. Не безопасно просто обращаться к myNode.nodeName и затем
использовать это значение; во многих ситуациях значение будет равно null.
Поэтому, как часто бывает в программировании, пусть побеспокоится
программист.
Общие типы узлов
Теперь, узнав о некоторых возможностях и свойствах DOM-узла (а также о
некоторых его странностях), вы готовы узнать о некоторых конкретных типах узлов,
с которыми будете работать. В большинстве Web-приложений вы будете работать
только с четырьмя типами узлов:
- Узел document представляет HTML-документ в целом.
- Узлы element представляют HTML-элементы, например
a или
img.
- Узлы attribute представляют атрибуты HTML-элементов, например
href (элемента a) или src (элемента
img).
- Узлы text представляют текст в HTML-документе, например "Нажмите на
ссылку ниже для получения полного списка". Это текст, появляющийся внутри таких
элементов как
p, a или h2.
При работе с HTML вы будете работать с этими типами узлов примерно 95%
времени. Поэтому я потрачу оставшуюся часть статьи этого месяца на их детальное
рассмотрение. Когда я буду рассматривать XML в будущей статье, то познакомлю вас
с некоторыми другими типами узлов.
Узел document
Первый тип узла - это тип, который вы будете использовать почти в каждом
фрагменте своего DOM-кода: узел document. Узел document на самом деле
является не элементом HTML (или XML) страницы, а самой страницей. Следовательно,
в HTML Web-странице узел document - это DOM-дерево полностью. В JavaScript вы
можете обратиться к узлу document при помощи ключевого слова
document:
// Эти две первые строки получают DOM-дерево текущей Web-страницы,
// и затем элемент <html> для этого дерева
var myDocument = document;
var htmlElement = myDocument.documentElement;
|
Ключевое слово document в JavaScript возвращает DOM-дерево
текущей Web-страницы. С этого момента вы можете работать с любыми узлами в
дереве.
Вы можете также использовать объект document для создания новых
узлов, используя следующие методы:
createElement(elementName) создает элемент с указанным именем.
createTextNode(text) создает новый текстовый узел с указанным
текстом.
createAttribute(attributeName) создает новый атрибут с
указанным именем.
Главное, что необходимо отметить - эти методы создают узлы, но не
присоединяют их или не вставляют их в какой-нибудь конкретный документ. Для
этого вы должны использовать один из уже рассмотренных методов, например
insertBefore() или appendChild(). Следовательно, для
создания и добавления нового элемента в документ вы можете использовать
следующий код:
var pElement = myDocument.createElement("p");
var text = myDocument.createTextNode("Here's some text in a p element.");
pElement.appendChild(text);
bodyElement.appendChild(pElement);
|
После использования элемента document для получения доступа к
DOM-дереву Web-страницы вы готовы начать работу непосредственно с элементами,
атрибутами и текстом.
Узлы element
Хотя вы будете часто работать с узлами element, многие из операций, которые
вы должны будете выполнять с элементами, включают методы и свойства, общие для
всех узлов, а не только для элементов. Только два набора методов специфичны для
элементов:
- Методы, относящиеся к работе с атрибутами:
getAttribute(name) возвращает значение атрибута с именем
name.
removeAttribute(name) удаляет атрибут с именем
name.
setAttribute(name, value) создает атрибут с именем
name и устанавливает его значение в value.
getAttributeNode(name) возвращает узел attribute с именем
name (узлы attribute описаны ниже).
removeAttributeNode(node) удаляет узел attribute,
соответствующий указанному node.
- Методы, относящиеся к поиску вложенных элементов:
getElementsByTagName(elementName) возвращает список узлов
элементов с указанным именем.
Это все довольно понятно, но все равно просмотрите некоторые примеры.
Работа с атрибутами
Работать с атрибутами довольно просто; например, вы можете создать новый
элемент img с объектом document и установить некоторые
из его атрибутов:
var imgElement = document.createElement("img");
imgElement.setAttribute("src", "http://www.headfirstlabs.com/Images/hraj_cover-150.jpg");
imgElement.setAttribute("width", "130");
imgElement.setAttribute("height", "150");
bodyElement.appendChild(imgElement);
|
Теперь это должно выглядеть однообразной работой. Фактически, вы должны
начать понимать, что если знаете концепцию узла и доступные методы, работа с DOM
в ваших Web-страницах и JavaScript-коде становится простой. В приведенном выше
коде JavaScript создает новый элемент img, устанавливает некоторые
атрибуты и добавляет его в тело HTML-страницы.
Поиск вложенных
элементов
Легко также найти вложенные элементы. Например, вот код, который я
использовал для поиска и удаления всех элементов img в
HTML-странице из листинга 3:
// Удалить все элементы <img> верхнего уровня из тела
if (bodyElement.hasChildNodes()) {
for (i=0; i<bodyElement.childNodes.length; i++) {
var currentNode = bodyElement.childNodes[i];
if (currentNode.nodeName.toLowerCase() == "img") {
bodyElement.removeChild(currentNode);
}
}
}
|
Вы можете достичь аналогичного эффекта, используя
getElementsByTagName():
// Удалить все элементы <img> верхнего уровня из тела
var imgElements = bodyElement.getElementsByTagName("img");
for (i=0; i<imgElements.length; i++) {
var imgElement = imgElements.item[i];
bodyElement.removeChild(imgElement);
}
|
Узлы attribute
DOM представляет атрибуты как узлы, и вы всегда можете получить атрибуты
элемента, используя свойство attributes элемента, как показано
ниже:
// Удалить все элементы <img> верхнего уровня из тела
var imgElements = bodyElement.getElementsByTagName("img");
for (i=0; i<imgElements.length; i++) {
var imgElement = imgElements.item[i];
// Вывести некоторую информацию об этом элементе
var msg = "Found an img element!";
var atts = imgElement.attributes;
for (j=0; j<atts.length; j++) {
var att = atts.item(j);
msg = msg + "\n " + att.nodeName + ": '" + att.nodeValue + "'";
}
alert(msg);
bodyElement.removeChild(imgElement);
}
|
|
Странная ситуация с атрибутами
Атрибуты - это немного особый случай в DOM. С одной стороны, атрибуты на
самом деле не являются потомками элементов, подобно другим элементам или тексту;
другими словами, они не появляются "под" элементом. В то же время они имеют
очевидную взаимосвязь с элементом; элемент "владеет" своими атрибутами. DOM
использует узлы для представления атрибутов и делает их доступными элементу
через специальный список. То есть, атрибуты являются частью DOM-дерева, но они
часто не появляются в дереве. Достаточно сказать, что взаимосвязь атрибутов с
остальной структурой DOM-дерева немного
туманна. | |
Стоит отметить, что свойство attributes на самом деле
принадлежит типу node, а не только типу element. Немного странно и не влияет на
ваше кодирование, но это надо знать.
Хотя определенно можно работать с узлами attribute, часто проще использовать
доступные для класса элемента методы для работы с атрибутами. Перечислим эти
методы:
getAttribute(name) возвращает значение атрибута с именем
name.
removeAttribute(name) удаляет атрибут с именем
name.
setAttribute(name, value) создает атрибут с именем
name и устанавливает его значение в value.
Эти три метода не требуют от вас работы непосредственно с узлами attribute.
Вместо них вы можете просто устанавливать и удалять атрибуты и их значения при
помощи простых строковых свойств.
Узлы text
Последний тип узла, о котором стоит позаботиться (по крайней мере, в HTML
DOM-деревьях), - это узел text. Почти все свойства, которые вы обычно будете
использовать с узлами text, доступны на объекте node. Фактически, вы будете
обычно использовать свойство nodeValue для получения текста из узла
text так, как показано ниже:
var pElements = bodyElement.getElementsByTagName("p");
for (i=0; i<pElements.length; i++) {
var pElement = pElements.item(i);
var text = pElement.firstChild.nodeValue;
alert(text);
}
|
Несколько других методов специфичны для узлов text. Они относятся к
добавлению или разбиению данных в узле:
appendData(text) добавляет предоставленный вами текст в конец
существующего в узле text текста.
insertData(position, text) позволяет вам вставлять данные в
середину узла text. Он вставляет предоставленный вами текст в указанную позицию.
replaceData(position, length, text) удаляет указанное
количество символов, начинающихся с указанной позиции, и помещает
предоставленный вами текст на место удаленного.
Какой тип узла?
Все, что вы видели до сих пор, предполагает, что вы уже знаете, с каким типом
узла работаете, хотя это не всегда так. Например, если вы перемещаетесь по
DOM-дереву и работаете с общими типами node, то не знаете, переместились ли на
элемент или на текст. Вы можете получить всех потомков элемента p и
не быть уверенным, работаете ли с текстом, с элементом b, или,
возможно, с элементом img. В этих случаях вы должны будете
определить тип узла перед тем, как сможете его использовать.
К счастью, определить это довольно просто. Тип DOM-узла определяет несколько
констант:
Node.ELEMENT_NODE - константа для типа узла element.
Node.ATTRIBUTE_NODE - константа для типа узла attribute.
Node.TEXT_NODE - константа для типа узла text.
Node.DOCUMENT_NODE - константа для типа узла document.
Существует несколько других типов узлов, но при работе с HTML вы редко будете
использовать какие-либо типы, кроме этих. Также я умышленно не привожу значений
каждой из этих констант, хотя они определены в спецификации DOM; вы никогда не
будете иметь дело со значениями непосредственно, поскольку именно для этого и
нужны константы!
Свойство nodeType
Вы можете также использовать свойство nodeType (которое
определяется для DOM-узла и поэтому доступно для всех узлов) для сравнения узла
с перечисленными выше константами, как показано ниже:
var someNode = document.documentElement.firstChild;
if (someNode.nodeType == Node.ELEMENT_NODE) {
alert("We've found an element node named " + someNode.nodeName);
} else if (someNode.nodeType == Node.TEXT_NODE) {
alert("It's a text node; the text is " + someNode.nodeValue);
} else if (someNode.nodeType == Node.ATTRIBUTE_NODE) {
alert("It's an attribute named " + someNode.nodeName
+ " with a value of '" + someNode.nodeValue + "'");
}
|
Это довольно простой пример, но его главный смысл - получение типа узла
является простой операцией. Более сложно определить, что делать с узлом
после того, как станет известен его тип; но, имея твердые знания того, что
предлагают типы node, text, attribute и elements, вы готовы взять
DOM-программирование в свои руки.
Хорошо, почти.
Искажение в работе
Похоже, что свойство nodeType является пропуском для работы с
узлами - оно позволяет вам определить тип узла, с которым вы работаете, и
написать код для работы с этим узлом. Проблема заключается в том, что
определенные выше константы Node не работают правильно в Internet
Explorer. То есть, если вы используете Node.ELEMENT_NODE,
Node.TEXT_NODE или любую другую константу в вашем коде, Internet
Explorer возвратит ошибку, аналогичную изображенной на рисунке
4.
Рисунок 4. Internet Explorer выдает
ошибку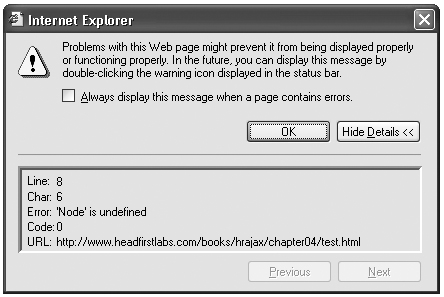
Internet Explorer всегда будет выдавать эту ошибку при использовании констант
Node в вашем JavaScript. Поскольку большинство людей в мире все
еще использует Internet Explorer, вы поступили бы правильно, избегая
использования в вашем коде таких конструкций как Node.ELEMENT_NODE или Node.TEXT_NODE. Даже если в
Internet Explorer 7.0 (в следующей версии Internet Explorer), предположительно,
эта проблема будет исправлена, пройдет не мало лет, пока Internet Explorer 6.x
выйдет из активного употребления. Потому избегайте использования Node; важно, чтобы ваш DOM-код (и ваши Ajax-приложения) работали на
всех главных браузерах.
В заключение
|
Вы готовы к славе?
Если вы действительно готовы к изучению и, в конечном счете, овладению DOM,
то будете находиться на вершине профессионального уровня в Web-программировании.
Большинство Web-программистов знает, как использовать JavaScript для написания
перебора изображений или сбора данных из формы, а некоторые даже чувствуют себя
комфортно, передавая запросы и получая ответы от сервера (это определенно должны
быть вы после прочтения первых нескольких статей данной серии). Но реальное
изменение структуры Web-страницы "на лету" - это не для слабонервных или
неопытных. | |
Вы узнали совсем не много в последних нескольких статьях этой серии. Теперь
вы не должны бездельничать и ждать следующей статьи, надеясь, что я
расскажу обо всех остроумных применениях DOM-дерева. Исследование того, как
можно создать необычные эффекты или искусные интерфейсы при помощи DOM, - это
сейчас ваше домашнее задание. Вспомните о том, что вы изучили в последних двух
статьях, и начните экспериментировать. Подумайте, сможете ли вы создать
Web-сайт, который выглядит как настольная прикладная программа, где объекты
перемещаются по экрану в ответ на действие пользователя.
Еще лучше, проведите границы вокруг каждого объекта на экране, так чтобы вы
смогли видеть, где находятся объекты в DOM-дереве, и начните перемещать их.
Создайте узлы и добавьте их к существующим спискам потомков; удалите узлы,
имеющие большое количество вложенных узлов; измените CSS-стиль узла и
посмотрите, повлияли ли эти изменения на дочерние узлы. Возможности безграничны,
и каждый раз, попытавшись сделать что-то новое, вы узнаете что-то новое. Удачи в
экспериментах с вашими Web-страницами.
Далее, в готовящейся финальной части этой DOM-трилогии, я покажу вам, как
внедрить некоторые замечательные и интересные применения DOM в ваше
программирование. Я перестану говорить концептуально и объяснять API, а покажу
некоторый код. А пока найдите какие-либо умные идеи и посмотрите, сможете ли вы
их воплотить самостоятельно.
Ресурсы
Научиться
- Оригинал статьи "Mastering
Ajax, Part 5: Manipulate the DOM".
- Предыдущие статьи этой серии developerWorks, знакомящие с Ajax:
- "Введение в
Ajax: Освоение Ajax, эффективный подход к созданию Web-сайтов и как эта
технология работает" Часть 1: демонстрирует, как компоненты технологии Ajax
работают совместно, и раскрывает центральные концепции Ajax, включая объект
XMLHttpRequest (декабрь 2005).
- "Выполнение
асинхронных запросов с JavaScript и Ajax: Использование XMLHttpRequest для
Web-запросов" Часть 2: показывает, как создать экземпляры XMLHttpRequest
способом, подходящим для разных браузеров, составлять и передавать запросы,
получать ответы от сервера (январь 2006).
- "Усовершенствованные
запросы и ответы в Ajax" Часть 3: демонстрирует, как стандартные Web-формы
работают с Ajax, и рассказывает о кодах состояния HTTP, состояниях готовности и
объекте XMLHttpRequest (февраль 2006).
- "Использование
DOM для создания Web-приложений с быстрой реакцией" Часть 4: знакомит с DOM
и объясняет, как преобразование HTML в объектную модель делает Web-страницы
отзывчивыми и интерактивными (март 2006).
- "Ajax для
Java-разработчиков: Создание динамичных Java-приложений", Philip McCarthy
(developerWorks, сентябрь 2005): Взгляните на Ajax со стороны сервера и языка
Java, познакомьтесь с принципиально новым подходом к созданию динамичных
Web-приложений.
- "Ajax для
Java-разработчиков: Сериализация Java-объектов для Ajax", Philip McCarthy
(developerWorks, октябрь 2005): Узнайте о пяти подходах к сериализации
Java-объектов, о передаче объектов по сети и взаимодействии с Ajax.
- "Вызов
SOAP Web-служб при помощи AJAX, Часть 1: Создание клиента Web-служб"
(developerWorks, октябрь 2005) – довольно продвинутая статья по интеграции Ajax
с существующими web-службами, основанными на SOAP. Узнайте, как реализовать
основанных на Web-браузере клиентов SOAP Web-служб, используя шаблон
проектирования Ajax.
- "Ajax:
Новый подход к Web-приложениям" – статья, создавшая понятия Ajax,
обязательна для чтения всеми Ajax-разработчиками.
- Домашняя страница DOM на World Wide Web
Consortium: Посетите отправной пункт для всего, что касается DOM.
- DOM Level
3 Core Specification: Определение основ Document Object Model, от доступных
типов и свойств до использования DOM в различных языках
программирования.
- "Правила
соединения языка ECMAScript с DOM": Если вы являетесь
JavaScript-программистом и хотите использовать DOM, это приложение к "Level 3
Document Object Model Core definitions" вас заинтересует.
- Технические
события и Web-трансляции на developerWorks: Следите за брифингами для
технических разработчиков.
- Зона Web Architecture на
developerWorks: Усовершенствуйте ваши навыки в Web-строительстве.
- "Head Rush
Ajax", Элизабет Фримэн, Эрик Фримэн и Брэт МакЛафлин (O'Reilly Media,
Inc., март 2006): Загружает идеи из этой статьи в вашу голову в стиле "Вперед
головой".
- "Java и XML",
вторая редакция, Брет Маклафлин (Август 2001, O'Reilly Media, Inc.): Обсуждение
автором преобразований XHTML и XML.
- "JavaScript:
Полное руководство", Дэвид Флэнаган (Ноябрь 2001, O'Reilly Media, Inc.):
Исчерпывающие инструкции по работе с JavaScript, динамическими Web-страницами, а
в готовящемся издании добавлены две главы по Ajax.
- "Вперед
головой в HTML с CSS & XHTML", Элизабет и Эрик Фримены (Декабрь
2005, O'Reilly Media, Inc.): Доскональный источник информации для изучения
XHTML, CSS и их объединении.
Получить продукты и
технологии
Обсудить
Об авторе
|
|

|
|
Брэт Маклафлин работает с компьютерами со времен Logo (помните маленький
треугольник?). За последние несколько лет он стал одним из наиболее известных
авторов и программистов сообщества по технологиям Java и XML. Он работал в
Nextel Communications над реализацией сложных корпоративных систем, в Lutris
Technologies, фактически, над созданием сервера приложений, а с недавнего
времени - в O'Reilly Media, Inc., где продолжает писать и редактировать книги по
данной тематике. Его готовящаяся книга "Head
Rush Ajax" рассматривает инновационный подход "Вперед головой" к изучению Ajax; она
пишется совместно с известными соавторами Эриком и Бет Фримэн. Его недавняя
книга "Java
5.0 Tiger: Заметки разработчика" является первой доступной книгой по
новейшей технологии Java, а его классическая "Java
и XML" остается одной из наиболее авторитетных работ по использованию
технологий XML в языке программирования Java. |

 Форум Программиста
Форум Программиста Новости
Новости Обзоры
Обзоры Магазин Программиста
Магазин Программиста Каталог ссылок
Каталог ссылок Поиск
Поиск Добавить файл
Добавить файл Обратная связь
Обратная связь 