|
Исходники
Статьи
Языки программирования
.NET Delphi Visual C++ Borland C++ Builder C/С++ и C# Базы Данных MySQL MSSQL Oracle PostgreSQL Interbase VisualFoxPro Веб-Мастеру PHP HTML Perl Java JavaScript Протоколы AJAX Технология Ajax Освоение Ajax Сети Беспроводные сети Локальные сети Сети хранения данных TCP/IP xDSL ATM Операционные системы Windows Linux Wap Книги и учебники
Скрипты
Новости
 Магазин программиста
|
Освоение Ajax: Часть 4. Использование DOM для создания Web-приложений с быстрой реакциейВодораздел между программистами (работающими с серверными приложениями) и Web-программистами (тратящими свое время на HTML, CSS и JavaScript) существует уже давно. Однако Document Object Model (DOM) ликвидировала пропасть и сделала работу с XML на сервере и с HTML на клиентском компьютере возможной и эффективной. В этой статье Брэт МакЛафлин знакомит с Document Object Model, объясняет ее использование в Web-страницах и начинает исследовать ее использование с JavaScript. Как и многие Web-программисты вы, возможно, работали с HTML. С HTML программисты начинают работу над Web-страницей; HTML часто является последней вещью, которую они делают по завершении работы с приложением или сайтом, вылизывая до последнего бита размещение, цвет или стиль. И, таким же обычным, как и использование HTML, является неправильное представление о том, что на самом деле происходит с HTML, когда он поступает в браузер для визуализации на экране. Перед тем как я углублюсь в то, что, по вашему мнению, может происходить (и почему это, вероятно, не правильно), я хочу прояснить информацию о процессах, вовлеченных в проектирование и обслуживание Web-страниц:
Хотя все это общеизвестно, вещи быстро становятся интересными. Фактически, огромное количество "вещей", происходящих между шагами 4 и 5, и является предметом рассмотрения данной статьи. Термин "вещь" действительно применим, поскольку большинство программистов никогда не задумываются о том, что действительно происходит с их размеченным документом, когда браузер пользователя запрашивает его для отображения:
Оказывается, ответом на все эти вопросы является Document Object Model. Поэтому давайте без излишней суеты углубимся в DOM. Для большинства программистов их работа заканчивается там, где начинается Web-браузер. Другими словами, закинув файл в каталог на вашем Web-сервере, вы обычно делаете пометку "сделано" и (с надеждой) никогда о нем больше не вспоминаете! Это отличная цель, когда нужно написать ясные, хорошо-организованные страницы; нет ничего плохого в ожидании того, что ваша разметка отображается должным образом во всех браузерах, с различными версиями CSS и JavaScript. Проблема заключается в том, что такой подход ограничивает понимание программистом того, что на самом деле происходит в браузере. Более важно то, что он ограничивает вашу способность обновлять, изменять и реструктуризировать Web-страницу динамически, используя JavaScript на стороне клиента. Избавимся от этого ограничения и даже повысим интерактивность ваших Web-сайтов. Как типичный Web-программист, вы, возможно, запускаете ваш текстовый редактор и IDE и начинаете вводить HTML, CSS или даже JavaScript. Легко думать обо всех этих тегах, селекторах и атрибутах только как о небольших задачах, которые вы решаете для того, чтобы сайт выглядел должным образом. Но вы должны расширить ваши представления за эти рамки - представьте, что вы организуете ваше содержимое. Не беспокойтесь, я обещаю, что не превращу это в лекцию о красоте разметки или о том, что вы должны понять истинный потенциал вашей Web-страницы или что-либо еще метафизическое. Что вы действительно должны понимать точно - это какова ваша роль в Web-разработке. Когда дело касается внешнего вида страницы, вы, в лучшем случае, можете только давать советы. Если вы предоставляете таблицу стилей CSS, пользователь может переопределить ваши варианты стиля. Когда вы предоставляете размер шрифта, браузер пользователя может изменить эти размеры для людей с проблемами зрения или масштабировать их для крупных мониторов (с одинаково крупными разрешениями). Даже выбранные вами цвета и гарнитуры шрифтов зависят от монитора пользователя и от установленных на его системе шрифтов. Конечно, здорово сделать из страницы шедевр, но на все это вы имеете не самое большое влияние. Единственное, что находится под вашим абсолютным контролем - структура
Web-страницы. Ваша разметка является неизменяемой, и пользователи не могут
испортить ее; их браузеры могут только извлечь ее с вашего Web-сервера и
отобразить (хотя и в стиле, больше соответствующем вкусу пользователя, а не
вашему). Но организация этой страницы (находится ли слово в данном параграфе,
или в другом теге Как только вы осознаете, что ваша разметка, на самом деле, только структура
страницы, то сможете взглянуть на нее по-другому. Вместо того, чтобы считать,
что тег Вы должны также четко понимать, что стиль и поведение (обработчики событий и JavaScript) применяются к этой структуре после ее создания. Разметка должна уже существовать перед тем, как с ней можно работать и накладывать стиль. То есть, так же как вы можете хранить CSS в отдельном файле от вашего HTML, структура вашей разметки отделена от ее стиля, форматирования и поведения. Хотя вы определенно можете менять стиль элемента или фрагмент текста из JavaScript, более интересным является действительное изменение структуры, на которой основана ваша разметка. Как только вы будете помнить, что ваша разметка обеспечивает только структуру или "скелет" для вашей страницы, вы будете "на коне". И более того, вы увидите, как браузер берет эту текстовую структуру и превращает ее во что-то намного более интересное - набор объектов, каждый из которых может изменяться, добавляться или удаляться.
Перед обсуждением Web-браузера стоит рассмотреть вопрос, почему обычный текст является абсолютно лучшим выбором для хранения вашего HTML-кода (дополнительная информация приведена в разделе "Некоторые дополнительные мысли о разметке"). Не вдаваясь глубоко в рассмотрение всех за и против, просто вспомните, что ваш HTML-код передается по сети в Web-браузер каждый раз при просмотре страницы (для простоты не будем учитывать кеширование и т.д.). Просто не существует более эффективного способа, чем передавать текст. Двоичные объекты, графическое представление страницы, реорганизованная разметка … все это труднее передать по сети, чем обычные текстовые файлы. Добавим сюда и особенности браузера. Современные браузеры позволяют пользователям менять размер текста, масштабировать изображения, загружать CSS или JavaScript для страницы (в большинстве случаев) и многое другое - это все препятствует передаче в браузер какого-либо графического представления страницы. Вместо этого браузер нуждается в сыром HTML-коде, для того чтобы он сам смог применить какую-либо обработку к странице, а не полагаться на сервер при выполнении этой задачи. Таким же образом, отделение CSS от JavaScript и отделение их от HTML-разметки требует формата, который легко было бы, да-да, разделять. Текстовые файлы опять же являются отличным способом сделать именно это. И последнее, но не менее важное: вспомните обещание новых стандартов HTML 4.01 и XHTML 1.0 и 1.1 отделить содержимое (данные вашей страницы) от представления и стиля (обычно выделенные в CSS). Для программистов отделение их HTML-кода от CSS и последующее указание браузеру извлечь некоторое представление страницы, описывающее методы повторного объединения всего, нивелируют многие преимущества этих стандартов. Хранение этих отдельных частей раздельно по всему пути до браузера обеспечивает браузерам наибольшую гибкость в получении HTML от сервера. Для некоторых из вас, все, что вы до сих пор прочитали, может быть забавным обзором вашей роли в процессе Web-разработки. Но когда дело доходит до вопроса, что же делает Web-браузер, многие из самых сообразительных Web-дизайнеров и разработчиков часто не представляют себе, что же на самом деле происходит "под капотом". Я рассмотрю это в данном разделе. И не беспокойтесь, код вскоре появится. Потерпите еще немного, поскольку четкое понимание процессов, происходящих в браузере, очень важно для корректной работы вашего кода. Хотя текстовая разметка имеет огромные преимущества для дизайнера или создателя страницы, она имеет довольно значительные недостатки для браузера. В частности, браузерам не просто непосредственно представить текстовую разметку пользователю визуально (дополнительная информация приведена в разделе "Некоторые дополнительные мысли о разметке"). Учитывайте следующие частые задачи браузера:
Сложность заключается не в кодировании этих задач; довольно просто выполнить
каждую из них. Сложность в браузере, выполняющем эти задачи. Если разметка
сохраняется в тексте и, например, вы хотите выровнять текст по центру
(
Эти трудные вопросы являются причиной, почему так мало людей занимается в настоящее время программированием браузеров (тем, кто делает это, нужно сказать искреннее "Спасибо!"). Очевидно, обычный текст - это не очень хороший способ хранения HTML для браузера, даже если текст и является хорошим решением для первоначального получения разметки страницы. Добавьте к этому способность JavaScript менять структуру страницы, и дело действительно станет мудреным. Должен ли браузер записать измененную структуру на диск? Как он может следить за текущим состоянием документа? Очевидно, текст не является ответом. Его трудно модифицировать, трудно применять стили и поведение, и, в конечном итоге, он служит слабым отражением динамической природы современных Web-страниц. Решением этой проблемы (по крайней мере, решением, выбранным в современных Web-браузерах) является использование древовидной структуры для представления HTML. Взгляните на листинг 1, где приведена довольно простая и скучная HTML-страница, представленная в виде текстовой разметки. Листинг 1. Простая HTML-страница в текстовой разметке
Браузер принимает ее и преобразовывает в древовидную структуру, изображенную на рисунке 1. Рисунок 1. Листинг 1 в виде дерева 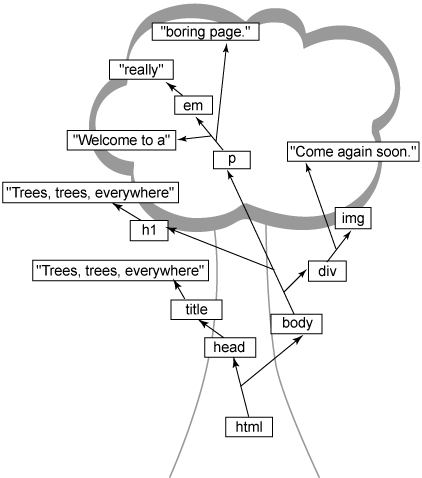 Я сделал несколько очень небольших упрощений для целей данной статьи. Эксперты в DOM или XML знают, что пробелы могут иметь влияние на представление текста в документе и на разбиение древовидной структуры в Web-браузере. Учет этого дает мало, а только запутывает дело, поэтому если вы знаете о влиянии пробелов - отлично; если нет, продолжайте чтение и не беспокойтесь об этом. Когда это станет важно, вы всегда найдете все необходимое. В отличие от действительной структуры дерева, первой вещью, которую вы можете
заметить, является то, что все в дереве начинается с самого внешнего,
всеохватывающего элемента HTML, которым является Из корня отходят линии, показывающие взаимоотношения между различными частями
разметки. Элементы
Продолжая метафору дерева, говорят, что Теперь, когда у вас на вооружении есть некоторая основная терминология, время сконцентрироваться на этих маленьких прямоугольничках с названиями элемента и текстом внутри (рисунок 1). Каждый прямоугольник является объектом; здесь браузер решает некоторые из описанных проблем с текстом. Используя объекты для представления каждого участка HTML-документа, становится очень просто менять структуру, применять стили, разрешать JavaScript получать доступ к документу и многое другое. Каждый возможный тип разметки получает свой собственный тип объекта.
Например, элементы в вашем HTML-коде представлены типом объекта
Итак, Web-браузер не только использует объектную модель для представления
вашего документа (устраняя необходимость иметь дело со статическим текстом), но
может немедленно рассказать о чем-нибудь по его типу объекта. HTML-документ
синтаксически анализируется и превращается в набор объектов, как вы видели на рисунке 1, и такие элементы, как угловые скобки и
escape-последовательности (например, использование Используя объекты, Web-браузер может изменить свойства этих объектов.
Например, каждый объект имеет родителя и список потомков. Поэтому добавление
нового дочернего элемента или текста представляет собой простое добавление
нового потомка в список потомков элемента. Эти объекты также имеют свойство
Другими словами, Web-браузер может очень просто изменить внешний вид и структуру дерева, используя подобные свойства объекта. Сравните это с теми сложными типами действий, которые браузер должен был делать, если бы страница внутренне представлялась в виде текста (каждое изменение свойства или структуры потребовало бы от браузера перезаписи статического файла, его повторного синтаксического анализа и повторного отображения на экране). Все это становится возможным с объектами. Теперь потратьте время на открытие какого-либо вашего HTML-документа и на схематическое представление его в виде дерева. Хотя это может показаться необычной просьбой (особенно в статье, содержащей очень малый объем кода), вы должны познакомиться со структурой этих деревьев, если хотите уметь управлять ими. Во время работы вы, возможно, обнаружите некоторые странности. Например, представьте следующие ситуации:
Познакомившись с такого рода проблемами, вы намного лучше поймете следующие несколько разделов. Если вы пробовали выполнить только что упомянутое мной упражнение, то,
возможно, обнаружили некоторые потенциальные проблемы при просмотре вашей
разметки в виде дерева (если вы упражнение не делали, просто поверьте мне на
слово!). Фактически, вы обнаружите некоторые из них в листинге 1 и на рисунке 1, начиная со
способа разбиения элемента Оказывается, что элемент Более того, порядок имеет значение! Вы можете представить себе, как реагировали бы пользователи Web-браузера, если бы он показывал корректную разметку, но в отличном от указанного вами в HTML-коде порядке? Параграфы наложились бы друг на друга между заголовками, хотя вы не так организовывали ваш документ? Очевидно, что браузер должен сохранять порядок элементов и текста. В данном случае элемент
Если вы перемешаете порядок, то можете выделить не ту часть текста. Для сохранения всего в нужном состоянии элемент p содержит дочерние объекты в том порядке, в котором они появляются в HTML (листинг 1). Более того, выделенный текст "really" не является дочерним элементом p; он - потомок em, который является потомком p. Для вас очень важно понимать эту концепцию. Даже если текст "really" будет
отображаться вместе с остальным текстом элемента Чтобы помочь закрепить все это в вашей голове, попробуйте нарисовать схему HTML из листингов 2 и 3, проверяя сохранение текста с его корректным предком (не смотря на то, как этот текст может в конечном итоге отображаться на экране). Листинг 2. Разметка с немного хитрой вложенностью элементов
Листинг 3. Еще более хитрая вложенность элементов
Вы найдете ответы на эти упражнения в GIF-файлах tricky-solution.gif (рисунок 2) и trickier-solution.gif (рисунок 3) в конце этой статьи. Не заглядывайте в них, пока не потратите время на самостоятельную работу. Это поможет понять, как строгие правила применяются к структуре дерева, и действительно поможет вам на пути к освоению HTML и его древовидной структуры. Сталкивались ли вы с какими-либо проблемами, когда определяли, что делать с атрибутами? Как я уже говорил, атрибуты имеют свой собственный тип объекта, но атрибут на самом деле не является потомком элемента, в котором появляется - вложенные элементы и текст не находятся на таком же "уровне" атрибута, и вы увидите, что ответы на упражнения из листингов 2 и 3 не показывают атрибуты. Атрибуты действительно хранятся в объектной модели, которую использует
браузер, но они имеют немного другое положение. Каждый элемент содержит список
доступных ему атрибутов отдельно от списка дочерних объектов. То есть,
элемент Помните, что атрибуты элемента должны иметь уникальные имена; другими
словами, элемент не может иметь два атрибута "id" или два атрибута "class". Это
позволяет хранить список и обращаться к нему очень просто. Как вы увидите в
следующей статье, вы можете просто вызвать метод, например,
Также стоит подчеркнуть, что уникальность имен атрибутов делает этот список
отличным от списка дочерних объектов. Элемент Прежде чем идти дальше, стоит потратить некоторое время еще на одну тему, связанную с преобразованием браузером разметок в древовидное представление, - как браузер справляется с разметкой, не являющейся грамматически правильной. Грамматически правильный - это термин, используемый в основном в XML. Он означает два основных правила:
Внимательно изучите два эти правила. Они не только упрощают структуру
документа, но и устраняют двусмысленность. Нужно сначала сделать шрифт жирным,
или наклонным? Или наоборот? Если этот порядок и двусмысленность кажется не
очень важным, помните о том, что CSS позволяет правилам переопределять другие
правила, то есть, если, например, шрифт текста внутри элементов В тех случаях, когда браузер получает документ, не являющийся грамматически правильным, он просто делает лучшее, на что способен. Получаемая древовидная структура является в лучшем случае аппроксимацией того, что намеревался передать автор оригинальной страницы, и в худшем - что-то совершенно другое. Если вы когда-то загружали вашу страницу в браузер и видели что-то абсолютно неожиданное, то значит вы видели результат безуспешных попыток браузера догадаться о структуре вашего документа. Естественно, исправить это довольно просто: проверьте, является ли ваш документ грамматически правильным! Если вы сомневаетесь в чем-то при написании таких стандартизированных HTML-страниц, обратитесь за помощью в раздел "Ресурсы". До сих пор вы слышали, что браузеры превращают Web-страницу в объектное представление, и возможно даже догадывались, что таким представлением является DOM-дерево. DOM обозначает Document Object Model и является спецификацией, доступной на World Wide Web Consortium (W3C) (вы можете проверить несколько связанных с DOM ссылок в разделе "Ресурсы"). Хотя более важно, что DOM определяет типы и свойства объектов - это позволяет браузерам представлять разметку (в следующей статье этой серии будут рассмотрены особенности использования DOM из вашего JavaScript и Ajax-кода). Первое, и самое главное, вам необходимо получить доступ к самой объектной
модели. Это удивительно просто; для использования встроенной переменной
Конечно, этот код совершенно бесполезен сам по себе, но он демонстрирует то,
что каждый браузер делает объект Несомненно, объект Если вы много программировали в JavaScript, то, возможно, уже использовали
DOM-код. Если вы до сих пор следовали этой Ajax-серии статей, то
определенно использовали DOM-код некоторое время. Например, строка
Уточним изученные вами понятия. DOM-дерево - это дерево объектов, точнее, дерево объектов node. В Ajax-приложениях (или в любом другом JavaScript-коде) вы можете работать с этими узлами для создания таких эффектов, как удаление элемента и его содержимого, цветовое выделение определенного фрагмента текста или добавление нового элемента изображения. Поскольку все это происходит на стороне клиента (в коде, работающем в вашем Web-браузере), эти эффекты выполняются немедленно, без обмена информацией с сервером. В конечном итоге, получаем приложение, являющееся более чувствительным, поскольку изменения Web-страницы происходят без длительных пауз, возникающих при передаче запроса на сервер и интерпретации ответа. В большинстве языков программирования вы должны изучить реальные имена объектов для каждого типа узла, изучить доступные свойства и узнать о типах и их преобразовании; но ничего этого не надо в JavaScript. Вы можете просто создать переменную и назначить ей желаемый объект (как вы уже видели):
Здесь нет типов; JavaScript управляет созданием переменных и назначением им корректных типов при необходимости. В результате использовать DOM в JavaScript становится довольно тривиальной задачей (в следующей статье будет рассматриваться DOM по отношению к XML и немного более сложные ситуации). Сейчас я собираюсь вас немного заинтриговать. Очевидно, что эта статья не была полностью исчерпывающим обзором DOM; фактически эта статья лишь немного больше, чем введение в DOM. DOM больше рассказанного мной сегодня! Следующая статья данной серии развивает эти идеи и детальнее рассматривает использование DOM в JavaScript для обновления Web-страниц, динамического изменения HTML и создания более интерактивных приложений для ваших пользователей. Я вернусь к DOM опять в следующих статьях при рассмотрении использования XML в ваших Ajax-запросах. Поэтому осваивайте DOM; это главная часть Ajax-приложений. Было бы довольно просто заняться сейчас DOM более интенсивно, подробно рассматривая перемещение в DOM-дереве, получение значений элементов и текста, итерацию по списку узлов и т.д., но это, возможно, оставило бы у вас ощущение, что DOM имеет отношение к коду, а это не так. Перед следующей статьей попробуйте подумать о структурах дерева и поработайте
с некоторыми вашими собственными HTML-страницами, посмотрите, как Web-браузер
преобразует эти HTML в древовидное представление разметки. Также продумайте
структуру DOM-дерева и проработайте специальные случаи, рассмотренные в этой
статье: атрибуты, текст, имеющий смесь элементов, элементы, не имеющие
текстового содержимого (например, элемент Если вы четко усвоите эти концепции и затем изучите синтаксис JavaScript и DOM (в следующей статье), это значительно облегчит создание интерактивных Web-приложений с быстрой реакцией. И не забывайте, здесь приведены ответы для листингов 2 и 3 - они тоже включены в код примеров! Рисунок 2. Ответ для листинга 2 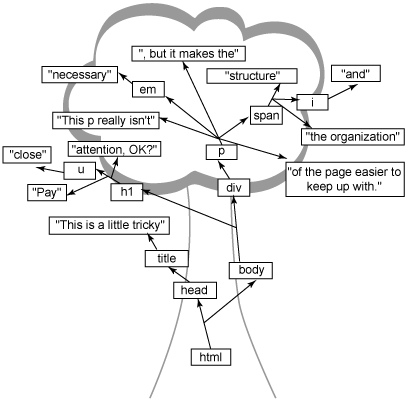 Рисунок 3. Ответ для листинга 3 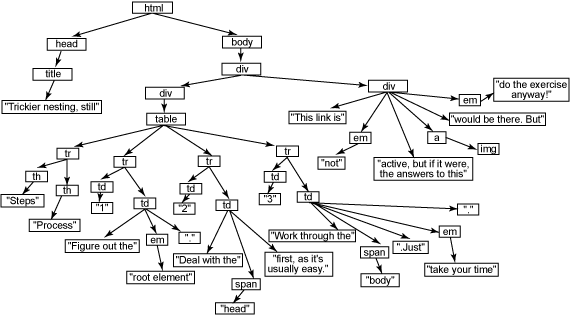
Получить продукты и технологии
Обсудить
|
 Форум Программиста
Форум Программиста Новости
Новости Обзоры
Обзоры Магазин Программиста
Магазин Программиста Каталог ссылок
Каталог ссылок Поиск
Поиск Добавить файл
Добавить файл Обратная связь
Обратная связь |
|||||||||||||||

